撰文:Tanya Malhotra
来源:Marktechpost
编译:DeFi 之道

图片来源:由无界版图AI工具生成
随着生成性人工智能在过去几个月的巨大成功,大型语言模型(LLM)正在不断改进。这些模型正在为一些值得注意的经济和社会转型做出贡献。OpenAI 开发的 ChatGPT 是一个自然语言处理模型,允许用户生成有意义的文本。不仅如此,它还可以回答问题,总结长段落,编写代码和电子邮件等。其他语言模型,如 Pathways 语言模型(PaLM)、Chinchilla 等,在模仿人类方面也有很好的表现。
Blockchain.com已暂停其资产管理部门:金色财经报道,Blockchain.com将暂停其资产管理部门业务。一份文件显示,Blockchain.com资产管理公司(BCAM)周一已申请取消注册,该公司目前尚未提交任何年度账目。BCAM于2022年4月推出,不久后宏观经济状况迅速恶化。该公司一位发言人在电子邮件中表示,随着加密货币冬天已持续近一年,我们做出了暂停运营该部门的商业决定。[2023/3/10 12:52:45]
大型语言模型使用强化学习(reinforcement learning,RL)来进行微调。强化学习是一种基于奖励系统的反馈驱动的机器学习方法。代理(agent)通过完成某些任务并观察这些行动的结果来学习在一个环境中的表现。代理在很好地完成一个任务后会得到积极的反馈,而完成地不好则会有相应的惩罚。像 ChatGPT 这样的 LLM 表现出的卓越性能都要归功于强化学习。
VeChain推出去中心化加密钱包VeWorld:金色财经报道,VeChain基金会宣布推出其新的去中心化自主钱包 VeWorld。该钱包可作为Chrome浏览器的一个扩展。移动和桌面版本将在2023年第三季度推出。新钱包为VeChain生态系统引入了许多改进,包括扩大的功能路线图。该组合将由一个专门的基金会开发人员团队每两周迭代升级一次。
该钱包允许用户创建和导入钱包,管理加密货币钱包,发送和接收加密货币,在去中心化应用程序上安全地进行交易,并使用Ledger设备管理加密资产。[2023/2/21 12:18:16]
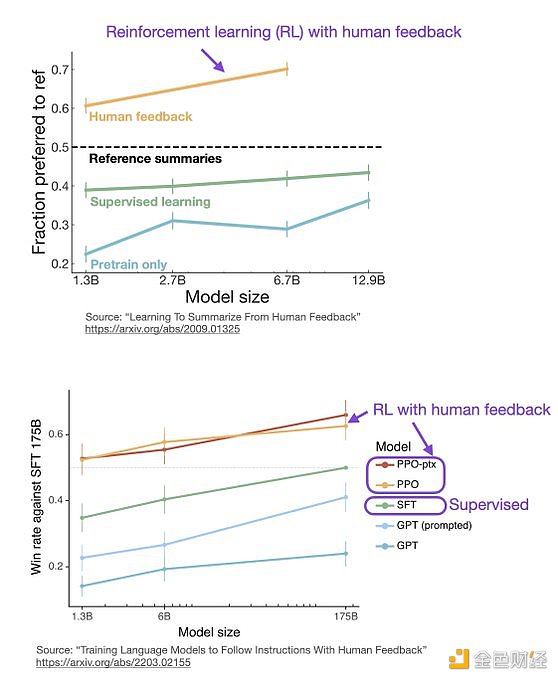
ChatGPT 使用来自人类反馈的强化学习(RLHF),通过最小化偏差对模型进行微调。但为什么不是监督学习(Supervised learning,SL)呢?一个基本的强化学习范式由用于训练模型的标签组成。但是为什么这些标签不能直接用于监督学习方法呢?人工智能和机器学习研究员 Sebastian Raschka 在他的推特上分享了一些原因,即为什么强化学习被用于微调而不是监督学习。
因BNB Chain持续拥堵,链游Zuki Moba决定完全迁移到 Polygon:3月22日消息,BNB Chain链游 Zuki Moba 发布公告表示,由于 BNB Chain 上交易持续拥塞以及交易速度慢,许多用户遭遇了交易中断问题,因此决定将 Dapp、NFT 和 ZUKI 代币、ZP 代币从 BNB Chain 完全迁移到 Polygon 网络。Zuki Moba 计划于4月在 Polygon 上线主网。
据悉,ZukiMoba是一款以去中心化经济应用社区为导向的MOBA电竞游戏(多人在线对战竞技场)。游戏内NFT用于构建角色、游戏物品和元宇宙结构。去年11月,该项目完成140万美元融资。(prnewswire)[2022/3/22 14:11:56]
太空链SpaceChain加入以太坊企业联盟:2月27日,太空链SpaceChain收到以太坊企业联盟(EEA)邀请,成为联盟正式成员。28日SpaceChain将与以太坊企业联盟执行总监Ron Resnick进行会议沟通,深度探讨双方合作细节。[2018/2/27]
不使用监督学习的第一个原因是,它只预测等级,不会产生连贯的反应;该模型只是学习给与训练集相似的反应打上高分,即使它们是不连贯的。另一方面,RLHF 则被训练来估计产生反应的质量,而不仅仅是排名分数。
Sebastian Raschka 分享了使用监督学习将任务重新表述为一个受限的优化问题的想法。损失函数结合了输出文本损失和奖励分数项。这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题-答案对时才能成功。但是累积奖励对于实现用户和 ChatGPT 之间的连贯对话也是必要的,而监督学习无法提供这种奖励。
不选择 SL 的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠 SL 是不够的,RLHF 对于考虑整个对话的背景和连贯性是必要的。
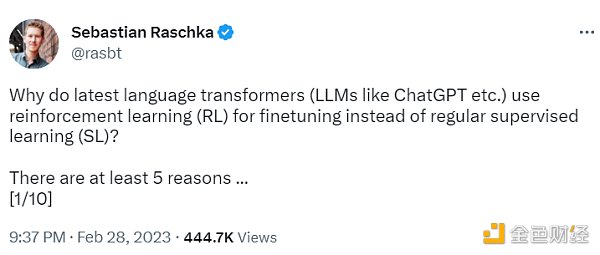
监督学习可以用来训练一个模型,但根据经验发现 RLHF 往往表现得更好。2022 年的一篇论文《从人类反馈中学习总结》显示,RLHF 比 SL 表现得更好。原因是 RLHF 考虑了连贯性对话的累积奖励,而 SL 由于其文本段落级的损失函数而未能很好做到这一点。
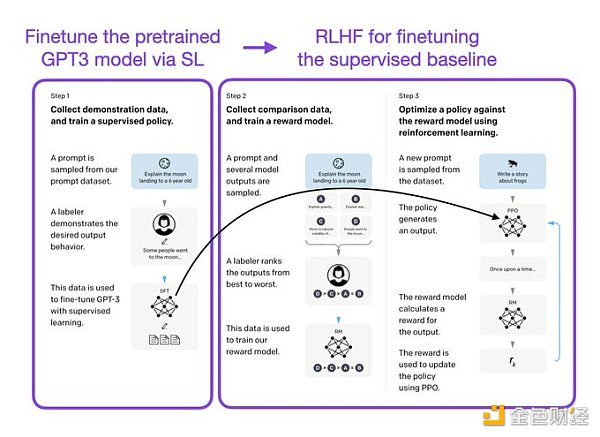
像 InstructGPT 和 ChatGPT 这样的 LLMs 同时使用监督学习和强化学习。这两者的结合对于实现最佳性能至关重要。在这些模型中,首先使用 SL 对模型进行微调,然后使用 RL 进一步更新。SL 阶段允许模型学习任务的基本结构和内容,而 RLHF 阶段则完善模型的反应以提高准确性。
DeFi之道
个人专栏
阅读更多
金色财经 善欧巴
金色早8点
Odaily星球日报
欧科云链
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新闻
Oort 去中心化边缘节点网络 (Oort DEN)的最新更新于2月27日发布。该网络已正式启动两周,旨在通过部署分布式边缘节点来提高 Web3 生态系统的安全性以.
1900/1/1 0:00:00最近团队小伙伴系统研究了市面上所有的AI工具,得出 2 个结论:1、无需焦虑,AI 工具虽多,但目前好用的不多;2、必须敬畏.
1900/1/1 0:00:00Adidas于2021年就已借助Web3开启数字化转型之路。2021年12月,在购买Bored Ape Yacht Club(BAYC)NFT后,Adidas Originals宣布与BAYC、.
1900/1/1 0:00:00原文:《当RaaS服务兴起:OP Stack能否威胁到Cosmos护城河?》当 OP Stack 这个方案被提出时,市场对于这项技术反响平平.
1900/1/1 0:00:00撰文:Jen Wiecener,New York features编译:angelilu,Foresight NewsBitMEX 联合创始人 Arthur Hayes 在结束 6 个月的软禁后.
1900/1/1 0:00:00撰文:Jason,Puzzle Ventures来源:Puzzle Ventures时至今日,Web3 已经吸引了一批技术大牛、金融玩家、风投机构和小部分投机者进入这个「疯狂的西部」.
1900/1/1 0:00:00