前言:隐私计算赛道作为当下的风口赛道,无数企业纷纷涌入,抢跑占道。作为一家专注于区块链隐私计算赛道科普入门的垂直媒体,同时也是针对隐私计算兴趣者开放的“纯天然”、低门槛入口,我们汇总并分类了隐私计算行业内晦涩难懂的名词,编写了「隐私计算词典」板块,帮助大家理解、学习。?
此篇,我们来了解隐私计算技术架构的第三部分——联邦学习。
近年来,从无人驾驶汽车,到AlphaGo击败顶尖的真人围棋手等等,AI人工智能在科技领域的发展着实吸引了足够多人的眼球。
然而,发展至今的AI人工智能仍面临两大现实问题:
行业数据分散且收集困难,数据以孤岛的形式存在;隐私得不到保障,安全共享数据成为了一道壁垒。针对此,人们提出了一种名为「联邦学习」的隐私计算技术。
Coinbase上线隐私计算网络Oasis (ROSE):4月26日消息,Coinbase 上线隐私计算网络 Oasis (ROSE),现已开放充值。若满足流动性条件,交易将于太平洋时间 4 月 26 日星期二上午 9 点或之后开始,分阶段推出 ROSE-USDT 交易对。[2022/4/26 5:11:15]
联邦学习,又名联邦机器学习、联合学习。它是AI人工智能的一门分支技术,旨在保障大数据交换时的信息安全、数据保护,在合法合规的前提下,有效帮助多行业的数据进行机器学习建模。

深耕区块链、隐私计算等领域,上海金融科技股权投资基金完成首轮关账签约:金色财经报道,上海国际集团下属国际资管和上海黄浦投资控股(集团)有限公司、嘉善县金融投资有限公司、横店集团控股有限公司等投资人就上海金融科技股权投资基金首关正式完成签约。上海金融科技股权投资基金将围绕数字经济新基建,深耕区块链、隐私计算等领域。[2021/10/24 6:10:27]
隐私保护是联邦学习最主要的关注点,在实际的应用中,联邦学习通过将数据的不同特征在加密的状态下加以聚合,以增强机器学习模型能力,再通过共享数据模型,避开原始数据共享,进而保证了数据的安全性。?
利用联邦学习的特点,即使是不导出企业数据的情况下,也能为三方或多方建立机器学习模型,既充分保护了数据隐私和数据安全,又为客户提供个性化、有针对性的服务,实现了互惠互利。?
交大复旦等联合筹建数字身份与数据流通信任技术实验室:开展隐私计算和区块链技术攻关:今年6月,我国颁布了《数据安全法》,9月1日将开始正式实施,上海市人大也正在起草《上海市数据条例》。近日,上海市数字证书认证中心、复旦大学计算机学院、上海交通大学电子信息与电气工程学院、移动互联网系统与应用安全国家工程实验室等宣布共同发起筹建数字身份与数据流通信任技术实验室,该实验室将基于数字信任技术的产学研生态合作,开展隐私计算、区块链、前沿密码等数字信任技术攻关和产业应用,支撑城市数字化转型、数据要素市场构建和网络安全体系建设。[2021/7/23 1:10:58]
同时,我们可以利用不同类别的联邦学习技术来解决数据异质性问题,突破传统AI技术的局限性。依照参与建模的数据源分布,联邦学习可分为横向联邦学习、纵向联邦学习和联邦迁移学习三类。?
蚂蚁链隐私计算平台通过信通院全项测评:金色财经报道,中国信息通信研究院大数据产品评测再度更新,根据中国信息通信研究院日前公布的评测结果,共计49家企业的106款产品通过了评审,其中,蚂蚁链数据隐私服务是本轮唯一通过全项能力测评的平台。为进一步完善数据所有权问题、数据共享、智能合约技术、协同计算等,信通院还同时牵头成立了“隐私计算联盟”。
据信通院透露,蚂蚁链数据隐私服务是本轮唯一通过全项能力测评的平台,也成为信通院“隐私计算联盟”的首批成员之一。
据悉,由蚂蚁链研发的数据隐私服务,集成了基于区块链的数字身份及授权体系,支持对数据隐私计算步骤、多方协作逻辑进行可信编程,降低隐私计算技术门槛,增强隐私计算协作治理、可信审计的技术能力,提供面向隐私信息全生命周期保护的技术能力。[2020/12/21 15:58:23]
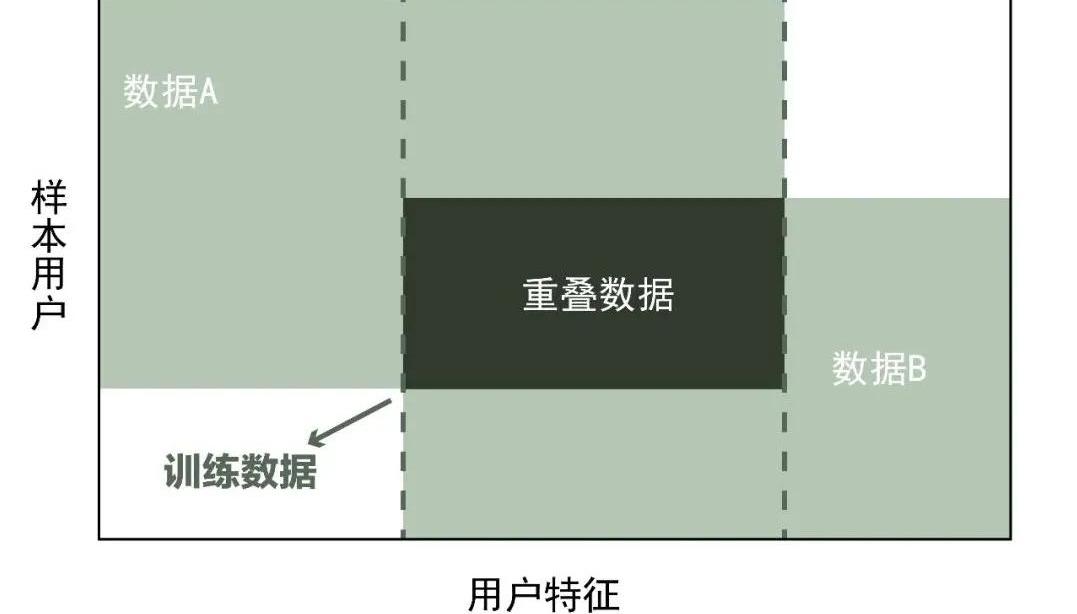
横向联邦学习假设收集两个数据集,这两个数据集用户特征重叠多,而用户重叠少。我们把数据集按照用户维度切分,取出双方用户特征相同,而用户不完全相同的部分数据作为机器的训练数据,这种模型称为横向联邦学习。?
动态 | 去中心化隐私计算方案ZEXE正式在Github上建立代码库:新的去中心化隐私计算方案ZEXE正式在Github上建立代码库。ZEXE 方案由研究人员Sean Bowe(Zcash)、Alessandro Chiesa(加州大学伯克利分校)、Matthew D. Green(约翰霍普金斯大学)等人通过论文《Zexe:Enabling Decentralized Private Computation》提出,利用包括零知识证明、递归证明合成等密码学知识,在保护数据隐私的前提下,实现高效的链下计算和链上验证。该方案目前尚处于学术概念验证阶段。[2019/4/7]
例如,两个不同行政区的银行,用户群体分别来自所在行政区,重叠部分少。但是同作为银行,业务类似,因此数据集收集的用户特征则大体相同。因此,横向联邦学习模型收集的是两个数据集不完全相同的用户部分。?
如下图所示:?
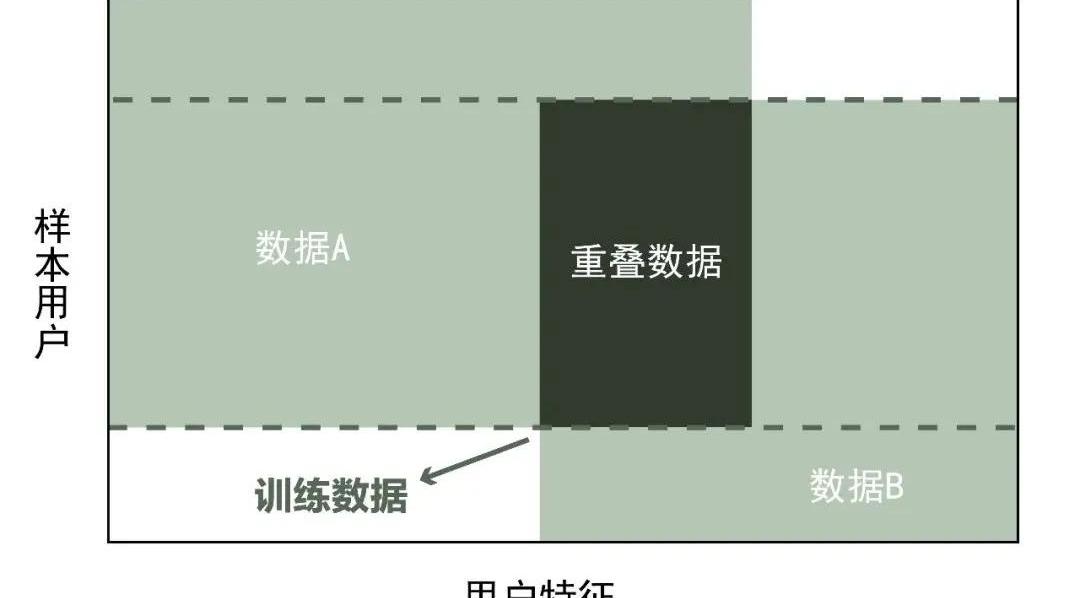
纵向联邦学习与横向联邦学习相反,在两个数据集用户重叠多、用户特征重叠少的情况下,纵向联邦学习把数据集按照数据特征维度切分,取出双方用户相同,而用户特征不完全相同的部分作为机器训练数据。?
例如,同一个行政区的银行和商超,其收集的数据用户群体大致类似,但银行和商超收集到的用户特征基本不同。因此,纵向联邦学习模型收集的是两个数据集不完全相同的用户特征部分。?
如下图所示:
联邦迁移学习在用于机器学习的数据集样本用户与用户特征重叠都较少的情况下,通常不对数据进行切分,而是引入联邦迁移学习,来解决数据不足的问题,从而提升模型的效果。
具体地,可以扩展已有的机器学习方法,使之具有横向联邦学习或者纵向联邦学习的能力。?例如,收集一家位于北京的银行和一家位于上海的商超的数据,由于受到地域限制,用户群体交集很小;同时,由于银行和商超类型的不同,二者收集的数据特征也基本无重合。?
引入联邦迁移学习,首先可以先让两个数据集训练各自的模型,之后通过加密模型数据,避免在传输中泄露隐私。之后,对这些模型进行联合训练,最后得出最优的模型,再返回给各个企业。?
如下图所示:?

多种类别的联邦学习方式使得机器学习模型更加具有通用性,可以在不同数据结构、不同行业间发挥作用,没有领域和算法限制,同时具有模型质量无损、保护隐私、确保数据安全的优势。?

在实际的应用中,类似销售、金融等行业,由于知识产权、隐私保护和数据安全等因素限制,数据壁垒很难打通。
联邦学习成为了解决这些问题的关键,在不影响数据隐私和安全的情况下,对来自多方的数据进行统一的建模,进行机器学习模型的训练,这些企业之间就能更好地进行数据协作。?
可以说,联邦学习为构建跨行业、跨地域的大数据和人工智能生态圈提供了良好的技术支持。?考虑到在整个训练过程中,进行模型更新的通信仍然可以向第三方或中央服务器显示敏感信息,因此联邦学习技术广泛地与安全多方计算、TEE或者区块链等技术结合应用,来增强联邦学习的隐私性和去信任。
但目前已有的方法通常以降低模型性能或系统效率为代价提供隐私,因此,如何在理论和经验上理解和平衡这些权衡,将是实现联邦学习技术广泛应用落地的一个相当大的挑战。
据印度《经济时报》12月9日消息,印度工业联合会(CII)建议政府将加密代币视为特殊类别的“证券”.
1900/1/1 0:00:00原标题:《元宇宙的若干治理和法律问题》年度热词:元宇宙。2021年12月元宇宙入选《柯林斯词典》2021年度热词、《咬文嚼字》2021年度十大流行语、国家语言资源监测与研究中心2021年度十大网.
1900/1/1 0:00:0012月2日,Ambire——一个基于DeFi的加密钱包在一轮融资计划中筹集了高达250万美元的资金。此次融资活动由LAUNCHHubVentures牵头.
1900/1/1 0:00:00原文:北青网 和著名歌手林俊杰做邻居,在现实中很难,在元宇宙中却容易得多。11月23日,林俊杰在推特上展示了他购买的三个虚拟地块,共花费约12.3万美元.
1900/1/1 0:00:00据Reddit以太坊子论坛披露消息称,100年前的1921年12月3日,美国福特汽车创始人亨利·福特(HenryFord)曾提出过与中本聪类似的数字货币想法.
1900/1/1 0:00:00基于UniswapV3的DeFi流动性协议VisorFinance再次遭受黑客攻击,黑客利用重入漏洞耗尽了880万枚VISR代币,当时,VISR的交易价格约为0.93美元.
1900/1/1 0:00:00