“Theonlysimpletruthisthatthereisnothingsimpleinthiscomplexuniverse.Everythingrelates.Everythingconnects”
—JohnnyRich,TheHumanScript
介绍
机器学习的主要应用之一是对随机过程建模。机器学习中一些随机过程的例子如下:
泊松过程:用于处理等待时间以及队列。随机漫步和布朗运动过程:用于交易算法。马尔可夫决策过程:常用于计算生物学和强化学习。高斯过程:用于回归和优化问题(如,超参数调优和自动机器学习)。自回归和移动平均过程:用于时间序列分析(如,ARIMA模型)。在本文中,我将简要地向你介绍这些随机过程。
历史背景
随机过程是我们日常生活的一部分。随机过程之所以如此特殊,是因为随机过程依赖于模型的初始条件。在上个世纪,许多数学家,如庞加莱,洛伦兹和图灵都被这个话题所吸引。
如今,这种行为被称为确定性混沌,它与真正的随机性有着截然不同的范围界限。
由于爱德华·诺顿·洛伦兹的贡献,混沌系统的研究在1963年取得了突破性进展。当时,洛伦兹正在研究如何改进天气预报。洛伦兹在他的分析中注意到,即使是大气中的微小扰动也能引起气候变化。
洛伦兹用来描述这种状态的一个著名的短语是:
“AbutterflyflappingitswingsinBrazilcanproduceatornadoinTexas”(在巴西,一只蝴蝶扇动翅膀就能在德克萨斯州制造龙卷风)—EdwardNortonLorenz(爱德华·诺顿·洛伦兹)
这就是为什么今天的混沌理论有时被称为“蝴蝶效应”。
分形学
一个简单的混沌系统的例子是分形(如图所示)。分形是在不同尺度上不断重复的一种模式。由于分形的缩放方式,分形不同于其他类型的几何图形。分形是递归驱动系统,能够捕获混沌行为。在现实生活中,分形的例子有:树、河、云、贝壳等。
SumSwap再次在opensea随机收购二枚会员定制NFT作品:据官方消息,7月3日,SumSwap再次在opensea以4000USDC一枚随机收购2枚会员定制NFT作品,截至目前SumSwap已花费1.6万USDC共收购4枚会员定制NFT。SumSwap共定制3000枚NFT作品,成功认购会员即免费赠送一枚NFT作品,SumSwap还将不定期用手续费回购NFT。当前SumSwap会员预售剩4000多区块,预计18小时左右结束会员预售。
?[2021/7/4 0:25:32]

图1:MC.Escher,SmallerandSmaller
在艺术领域有很多自相似的图形。毫无疑问,MC.Escher是最著名的艺术家之一,他的作品灵感来自数学。事实上,在他的画中反复出现各种不可能的物体,如彭罗斯三角形和莫比乌斯带。在"SmallerandSmaller"中,他也反复使用了自相似性(图1)。除了蜥蜴的外环,画中的内部图案也是自相似性的。每重复一次,它就包含一个有一半尺度的复制图案。
确定性和随机性过程
有两种主要的随机过程:确定性和随机性。
在确定性过程中,如果我们知道一系列事件的初始条件(起始点),我们就可以预测该序列的下一步。相反,在随机过程中,如果我们知道初始条件,我们不能完全确定接下来的步骤是什么。这是因为这个过程可能会以许多不同的方式演化。
在确定性过程中,所有后续步骤的概率都为1。另一方面,随机性随机过程的情况则不然。
任何完全随机的东西对我们都没有任何用处,除非我们能识别出其中的模式。在随机过程中,每个单独的事件都是随机的,尽管可以识别出连接这些事件的隐藏模式。这样,我们的随机过程就被揭开了神秘的面纱,我们就能够对未来的事件做出准确的预测。
TAAL提交新专利申请 专利涉及生成高质量的随机数:TAAL分布式信息技术公司(TAAL)宣布,其运营子公司已经向英国专利局提交了一份专利申请。TAAL认为,除了生成区块和保护区块链之外,部署在数据中心(即矿场)的计算能力还可以用于其他用途。据悉,该专利涉及生成大量高质量的随机数。过去,由于需要随机的环境输入,这些随机数的生成既繁琐又昂贵。反过来,这些高质量的随机数有多个用例,可用于复杂的计算应用程序,如可用于科学、医疗跟踪研究的人工智能(AI)建模场景以及高需求的金融计算机模拟。(美通社)[2020/4/3]
为了用统计学的术语来描述随机过程,我们可以给出以下定义:
观测值:一次试验的结果。总体:所有可能的观测值,可以记为一个试验。样本:从独立试验中收集的一组结果。例如,抛一枚均匀硬币是一个随机过程,但由于大数定律,我们知道,如果进行大量的试验,我们将得到大约相同数量的正面和反面。
大数定律指出:
“随着样本规模的增大,样本的均值将更接近总体的均值或期望值。因此,当样本容量趋于无穷时,样本均值收敛于总体均值。重要的一点是样本中的观测必须是相互独立的。”--JasonBrownlee
随机过程的例子有股票市场和医学数据,如血压和脑电图分析。
泊松过程
泊松过程用于对一系列离散事件建模,在这些事件中,我们知道不同事件发生的平均时间,但我们不知道这些事件确切在何时发生。
如果一个随机过程能够满足以下条件,则可以认为它属于泊松过程:
事件彼此独立(如果一个事件发生,并不会影响另一个事件发生的概率)。两个事件不能同时发生。事件的平均发生比率是恒定的。让我们以停电为例。电力供应商可能会宣传平均每10个月就会断电一次,但我们不能准确地说出下一次断电的时间。例如,如果发生了严重问题,可能会连续停电2-3天(如,让公司需要对电源供应做一些调整),以便在接下来的两天继续使用。
动态 | PeckShield: EOS竞猜游戏HotDice今晨遭随机数破解:据 PeckShield 态势感知平台01月04日数据显示:今日凌晨02:10-02:24之间,黑客向EOS竞猜类游戏HotDice游戏发起攻击,并不当获利转至交易所。我们注意到, 该HotDice游戏刚刚于1月2日下午上线,不到两天时间就被攻破。PeckShield安全人员认为目前的EOS竞猜类游戏屡遭黑客攻破,在于开发者没能对合约类高危账户及已标为黑名单的账户缺乏有效检测、阻断和隔离举措。[2019/1/4]
因此,对于这种类型的随机过程,我们可以相当确定事件之间的平均时间,但它们是在随机的间隔时间内发生的。
由泊松过程,我们可以得到一个泊松分布,它可以用来推导出不同事件发生之间的等待时间的概率,或者一个时间段内可能发生事件的数量。
泊松分布可以使用下面的公式来建模(图2),其中k表示一个时期内可能发生的事件的预期数量。
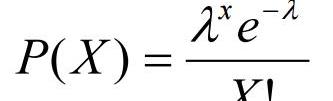
图2:泊松分布公式
一些可以使用泊松过程模拟的现象的例子是原子的放射性衰变和股票市场分析。
随机漫步和布朗运动过程
随机漫步是可以在随机方向上移动的任意离散步的序列(长度总是相同)(图3)。随机漫步可以发生在任何维度空间中(如:1D,2D,nD)。

图3:高维空间中的随机漫步
现在我将用一维空间(数轴)向您介绍随机漫步,这里解释的这些概念也适用于更高维度。
动态 | EOS竞猜游戏Lucky Nuts因随机数安全问题暂停:据 PeckShield 态势感知平台12月26日数据显示:今天凌晨02:36-05:11之间, 黑客向Lucky Nuts游戏合约(nutsgambling)重放多笔具有相同内容的交易,并持续从中获利。最终将大部分不当EOS获利转向币安交易所账号(binancecleos)。目前游戏合约已暂停交易,截至发稿时还处在维护状态。PeckShield 安全人员初步研究发现,此次是因游戏合约随机数问题被攻破。PeckShield在此提醒广大游戏开发者和游戏玩家,警惕安全风险。[2018/12/26]
我们假设我们在一个公园里,我们看到一只狗在寻找食物。它目前在数轴上的位置为0,它向左或向右移动找到食物的概率相等(图4)。
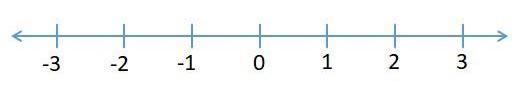
图4:数轴
现在,如果我们想知道在N步之后狗的位置是多少,我们可以再次利用大数定律。利用这个定律,我们会发现当N趋于无穷时,我们的狗可能会回到它的起点。无论如何,此时这种情况并没有多大用处。
因此,我们可以尝试使用均方根(RMS)作为距离度量(首先对所有值求平方,然后计算它们的平均值,最后对结果求平方根)。这样,所有的负数都变成正数,平均值不再等于零。
在这个例子中,使用RMS我们会发现,如果我们的狗走了100步,它平均会从原点移动10步(√100=10)。
如前面所述,随机漫步用于描述离散时间过程。相反,布朗运动可以用来描述连续时间的随机漫步。
隐马尔科夫模型
隐马尔可夫模型都是关于认识序列信号的。它们在数据科学领域有大量应用,例如:
计算生物学。写作/语音识别。自然语言处理(NLP)。强化学习HMMs是一种概率图形模型,用于从一组可观察状态预测隐藏(未知)状态序列。
动态 | EOSDice由于随机因子被操纵再次被黑:链安科技团队对11月10日发生的EOSDice随机数再次被攻击事件进行分析后发现,bocai新的随机数用到了其他一些账户的余额,攻击者模拟开奖流程action,然后在action中通过给随机因子中的账户(newdexpocket)转账来控制随机因子 ,操纵开奖结果。本次攻击手段利用了余额这个随机因子,较之前有所不同。安全团队再次提醒游戏开发者警惕可控的随机数算法因子,预防伪随机数漏洞。[2018/11/10]
这类模型遵循马尔可夫过程假设:
“鉴于我们知道现在,所以未来是独立于过去的"
因此,在处理隐马尔可夫模型时,我们只需要知道我们的当前状态,以便预测下一个状态(我们不需要任何关于前一个状态的信息)。
要使用HMMs进行预测,我们只需要计算隐藏状态的联合概率,然后选择产生最高概率(最有可能发生)的序列。
为了计算联合概率,我们需要以下三种信息:
初始状态:任意一个隐藏状态下开始序列的初始概率。转移概率:从一个隐藏状态转移到另一个隐藏状态的概率。发射概率:从隐藏状态移动到观测状态的概率举个简单的例子,假设我们正试图根据一群人的穿着来预测明天的天气是什么(图5)。
在这种例子中,不同类型的天气将成为我们的隐藏状态。晴天,刮风和下雨)和穿的衣服类型将是我们可以观察到的状态(如,t恤,长裤和夹克)。初始状态是这个序列的起点。转换概率,表示的是从一种天气转换到另一种天气的可能性。最后,发射概率是根据前一天的天气,某人穿某件衣服的概率。
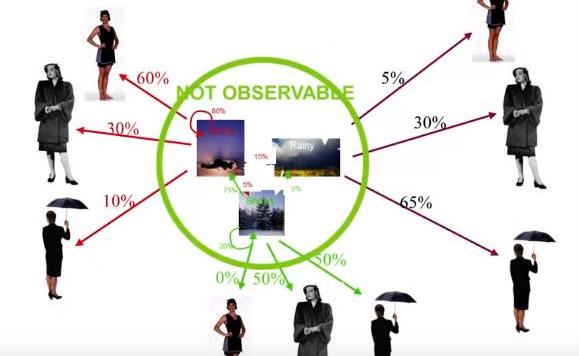
图5:隐马尔可夫模型示例
使用隐马尔可夫模型的一个主要问题是,随着状态数的增加,概率和可能状态的数量呈指数增长。为了解决这个问题,可以使用维特比算法。
如果您对使用HMMs和生物学中的Viterbi算法的实际代码示例感兴趣,可以在我的Github代码库中找到它。
从机器学习的角度来看,观察值组成了我们的训练数据,隐藏状态的数量组成了我们要调优的超参数。
机器学习中HMMs最常见的应用之一是agent-based情景,如强化学习(图6)。
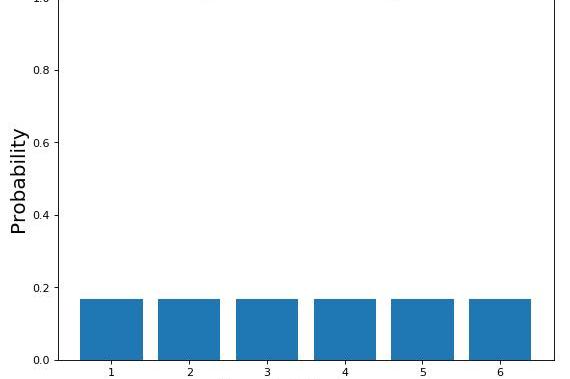
图7:掷骰子公平的概率分布
无论如何,你玩得越多,你就越可以看到到骰子总是落在相同的面上。此时,您开始考虑骰子可能是不公平的,因此您改变了关于概率分布的最初信念(图8)。
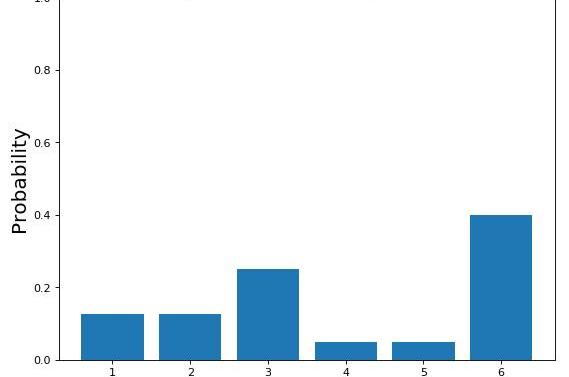
图8:不公平骰子的概率分布
这个过程被称为贝叶斯推理。
贝叶斯推理是我们在获得新证据的基础上更新自己对世界的认知的过程。
我们从一个先前的信念开始,一旦我们用全新的信息更新它,我们就构建了一个后验信念。这种推理同样适用于离散分布和连续分布。
因此,高斯过程允许我们描述概率分布,一旦我们收集到新的训练数据,我们就可以使用贝叶斯法则(图9)更新分布。
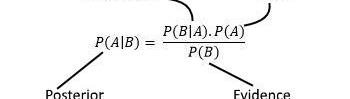
图9:贝叶斯法则
自回归移动平均过程
自回归移动平均(ARMA)过程是一类非常重要的分析时间序列的随机过程。ARMA模型的特点是它们的自协方差函数只依赖于有限数量的未知参数(对于高斯过程是不可能的)。
缩略词ARMA可以分为两个主要部分:
自回归=模型利用了预先定义的滞后观测值与当前滞后观测值之间的联系。移动平均=模型利用了残差与观测值之间的关系。ARMA模型利用两个主要参数(p,q),分别为:
p=滞后观测次数。q=移动平均窗口的大小。ARMA过程假设一个时间序列在一个常数均值附近均匀波动。如果我们试图分析一个不遵循这种模式的时间序列,那么这个序列将需要被差分,直到分割后的序列具有平稳性。
这可以通过使用一个ARIMA模型来实现,如果你有兴趣了解更多,我写了一篇关于使用ARIMA进行股票市场分析的文章。
谢谢阅读!
参考文献
MCEscher,“SmallerandSmaller”—1956.访问:https://www.etsy.com/listing/288848445/m-c-escher-print-escher-art-smaller-and
机器学习中大数定律的简要介绍。MachineLearningMastery,JasonBrownlee.访问:https://machinelearningmastery.com/a-gentle-introduction-to-the-law-of-large-numbers-in-machine-learning/
正态分布,二项分布,泊松分布,MakeMeAnalyst.访问:http://makemeanalyst.com/wp-content/uploads/2017/05/Poisson-Distribution-Formula.png
通用维基百科.Accessedat:https://commons.wikimedia.org/wiki/File:Random_walk_25000.gif
数轴是什么?MathematicsMonste.访问:https://www.mathematics-monster.com/lessons/number_line.html
机器学习算法:SD(σ)-贝叶斯算法.SagiShaier,Medium.访问:https://towardsdatascience.com/ml-algorithms-one-sd-%CF%83-bayesian-algorithms-b59785da792a
DeepMind的人工智能正在自学跑酷,结果非常令人惊讶。TheVerge,JamesVincent.访问:https://www.theverge.com/tldr/2017/7/10/15946542/deepmind-parkour-agent-reinforcement-learning
为数据科学专业人员写的强大的贝叶斯定理介绍。KHYATIMAHENDRU,AnalyticsVidhya.Accessedat:https://www.analyticsvidhya.com/blog/2019/06/introduction-powerful-bayes-theorem-data-science/
viahttps://towardsdatascience.com/stochastic-processes-analysis-f0a116999e4
今日资源推荐:AI入门、大数据、机器学习免费教程
35本世界顶级原本教程限时开放,这类书单由知名数据科学网站KDnuggets的副主编,同时也是资深的数据科学家、深度学习技术爱好者的MatthewMayo推荐,他在机器学习和数据科学领域具有丰富的科研和从业经验。
点击链接即可获取:https://ai.yanxishe.com/page/resourceDetail/417
雷锋网雷锋网雷锋网
457万美金的“巴菲特午餐”,已沦为孙晨宇巨幅广告牌近两个月。这顿天价午餐,到底什么时候才能吃上?自从6月4日,拍下457万美金天价的“巴菲特午餐”后,“孙晨宇”这个名字就成为了热搜榜上的常客.
1900/1/1 0:00:00作者:互链脉搏·金走车、元尚互链脉搏按:2019年8月5日,人民币离岸和在岸对美元汇率双双破“7”。8月6日,美国将中国列入所谓的“汇率操纵国”,一时间资本市场“腥风血雨”.
1900/1/1 0:00:00比特币现价:11886美元,下方小支撑11500点,下方强支撑11200点,上方小压力12000点,上方强压力12500点。预计比特币突破12000点上方概率较大.
1900/1/1 0:00:0010月8日,在日本大阪举行的年度以太坊开发者大会Devcon5上,企业以太坊联盟展示了其创建的奖励代币系统,由微软和英特尔支持.
1900/1/1 0:00:00又一批F-35部署半岛,重磅协议震彻亚太,萨德仅仅只是开始!据韩国媒体9月2日最新报道,消息援引自韩国政府某高官的表态,该报道表示,目前韩国和美国之间的军事合作还在进一步加深.
1900/1/1 0:00:00日本,国名之意是“日出之国”,是世界上的发达国家。它也是个多山的岛国,相信大家都听说过富士山,它是日本的最高峰.
1900/1/1 0:00:00