上面的图像是由一个人工智能绘制的,当时我们让它为“异常检测”这个词创作艺术品。
据《华盛顿邮报》报道,2009年至2010年间,英国有1.7万名男性报告怀孕。这些英国男性寻求与怀孕相关的护理,如产科检查和产妇护理服务。然而,这并不是因为现代医学的突破!有人在国家的医疗系统中输入了错误的医疗代码。简单地说,数据记录得很糟糕,而且没有质量检查来发现错误!
这很难归咎于英国的医疗服务。质量,顾名思义,是主观的。为各种可能的错误数据创建质量检查是一项巨大的壮举。即使是数据最成熟的公司也很难预料到每一个错误。然而,如果有一种方法可以使用AI/ML,这些解决方案可以独立地从我们的数据集中学习。他们可以发现这样的错误,而不需要我们明确地说,“如果入境的是男性,那么就不要提供孕产护理。”
事实上,有。
CPDA数据分析师都知道这叫做异常检测。
什么是数据质量检查?
在我们进入异常检测的奇迹之前,我们必须了解什么是数据质量检查(以及它是如何工作的)。
调查:大多数人根本不知道Web3是什么:金色财经报道,在民意调查公司YouGov与以太坊软件公司Consensys最近进行的一项调查中,全球各地的人们被问及他们对新兴技术的认识、他们对互联网经济状况的看法。调查发现,即使听说过,也没有多少人知道Web3是什么。在4月26日至5月18日期间对15个国家的15,000多人进行了调查。他们被问到了32个问题,与Web3、加密货币以及他们对当前互联网生态系统的看法有关。调查显示,全球24%的受访者表示至少了解Web3,但只有8%的人表示非常熟悉,16%的人表示有些熟悉。相比之下,37%的人表示他们根本不知道Web3。[2023/6/28 22:04:25]
数据质量检查指定了数据维度的标准,即数据的完整性、有效性、及时性、唯一性、准确性和一致性。数据要么不符合这些标准,要么满足这些标准,这揭示了有关其质量的信息(是高质量还是低质量)。您可以在这里了解更多关于数据质量及其重要性的信息。
数据质量规则将指定用户定义为高质量数据的内容。例如,医院可能将老年患者定义为年龄超过60岁。一个简单的数据质量规则可以有以下形式:
规则:老年患者年龄>60岁
实际上,每家医院可能都有不同的老年患者定义标准。因此,他们可能以不同的方式定义这些规则。通过这种方式,公司可以定义各种规则来识别有问题的数据。然后将这些规则添加到“规则库”中,并在数据质量监控期间用于识别低质量条目。
美国参议员:从政策制定的角度来看,拥有比特币与拥有牛没有什么不同:金色财经报道,美国参议员Cynthia Lummis正准备推出负责任的金融创新法案,这将影响加密货币的征税方式。她表示,从政策制定的角度来看,拥有比特币与拥有牛没有什么不同。作为2020年上任的参议员,Lummis 报告称持有价值 50,000 至 100,000 美元的 BTC,2021 年 8 月,她报告额外购买了价值 50,000 至 100,000 美元的 BTC。她没有从出售资产中获得任何收入。(decrypt)[2022/4/2 13:59:51]
一旦您的公司填充了这个规则库,您将开发一个您希望数据遵守的标准或“常规行为”。不符合这些标准的数据是无效的、不完整的、不准确的。
例如,在我们上面的高级患者规则中,如果一个申请人的年龄是35岁,而用户将其标记为“高级患者”,则此数据点将无效。
什么是异常检测?
然而,还有一种方法可以在不需要编写DQ规则的情况下找到与通常行为不同的数据点。这叫做异常检测。它使用ML/AI来扫描数据,而不是DQ规则,以发现数据集特有的模式和期望值。一旦它了解了您的数据系统是如何工作的,它就可以自动找到不符合规范(或不符合这些模式)的数据,并标记条目以提醒相关方。不符合这些标准的值被称为“异常值”。
播客主持人:当下的孩子们或许知道比特币是什么:播客节目“Magic Internet Money”主持人Brad Mills发推称:“我在万圣节糖果盒里放了一些价值100美元的Rise Wallet比特币卡,捕捉到了一些随机的‘不给糖就捣蛋’的人发现它们的瞬间。‘嘿哥们,我发现了比特币!’我想这些孩子们或许确实知道比特币是什么。”[2020/11/1 11:22:05]
一旦收到关于异常的警报,您将发现关于异常检测服务为什么将该条目标记为异常的信息。例如,假设一家医院在2月份记录了10,000名患者,医疗保健系统收到一个警报,将此条目标记为异常。它可以通过数据集中的上下文解释:这家医院通常每月有大约1000名患者。这种突然的跳跃是出乎意料的(或者显示为传达此信息的图形)。
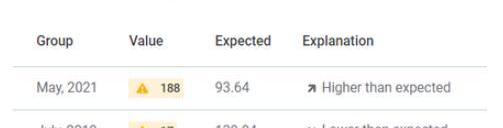
然后,您可以获取这些信息,并确定它是一个异常数据点还是一个正常数据点。也许是因为新冠肺炎,那家医院的病人激增了。根据您的响应方式,一些异常检测算法可以从这种反馈中学习,并在未来更加准确地检测异常。
在我们上面介绍医院的例子中,假设所有申请怀孕相关服务的人都被贴上了“PREG”的标签。如果绝大多数使用这些服务的患者在性别栏中有“F”(女性),异常检测就会立即注意到“M”(男性)患者是否接受了“PREG”标签。你不需要写规则“PREG必须是F”来防止这种错误发生。
Blockstream CEO 抨击以太坊、Ripple和庞氏局没什么两样:Blockstream首席执行官Adam Back 5日在Twitter称,“Bitconnect,Charles Ponzi,以太坊,Onecoin,Cardano,Ripple,Bernie Madoff,Stellar和Dan Larmer。这些看上去都非常相似。”据悉,Charles Ponzi和Bernie Madoff是庞氏局的两个最著名的创造者,而Bitconnect和OneCoin是被发现是庞氏局的著名加密货币项目,Back将此类局与以太坊、Ripple和Stellar,以及Dan Larmer(BM)相类比。[2020/8/6]
不同类型的异常
不同的业务角色有不同的方法来定义数据中的异常。
营销团队可能会收到异常数量的网络研讨会注册,从一个公司的域名收到比平时更多的入站请求,或者从一个国家收到太多的请求(超过正常)。这些异常会影响他们的工作表现,并被标记为关键。
数据工程师可能对两个不同系统中关于同一实体(如客户)的冲突信息更感兴趣。
数据科学家可能会看到2月份某个随机周四的平均销售数据。然而,周四是公共假日,预计销售额将增长两倍。这肯定也是一个关键的异常!
IT记者刘韧:区块链和互联网一样是创业公司机会,没BAT什么事:知名IT记者刘韧今日发表朋友圈说:“1996年到2004年,我对互联网的错误认识。1.1998年完成《知识英雄》,可以去做门户,但我选择写作《企业方法》,我当时的想法和现在很多人对区块链的认识相同,互联网还处在早期,我先将中国IT史写完,互联网机会有的是,等技术成熟了,我再介入不迟。结果到2000年我只有做Donews的机会了。2.《中国.com》很多篇幅写联想怎样转型互联网。我提问《杨元庆会不会掉队?》但依然看好杨元庆。区块链和互联网一样是创业公司机会,没BAT什么事,更不必去看京东的白皮书。3.以传统企业为本,传统企业崇拜,但传统企业使用互联网或互联网化,和互联网公司是两码事。今天传统企业Tokenize,肯定也不是区块链公司,别跟。”[2018/3/22]
因此,您可以说异常定义和异常检测是相当主观的。需要记住的重要部分是异常检测服务必须能够检测所有形式的异常。在Ataccama,我们喜欢根据异常与数据的接近程度来定义异常。从高层(远离实际数据,关于数据本身的更一般的信息)到低层(数据列中的异常,逐行,特定值/数据点),我们可以在三个类别中定义异常:元数据、事务数据和记录数据。
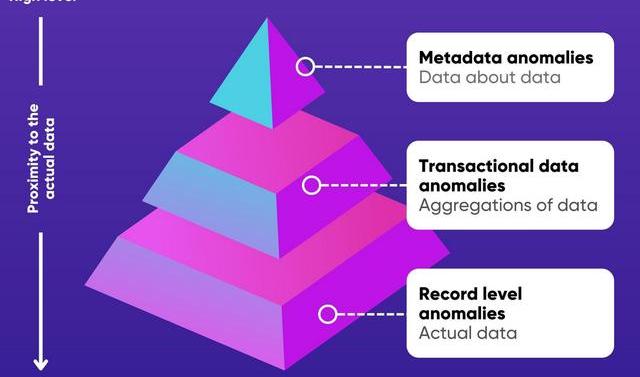
元数据异常
元数据是使用度量来描述实际底层数据的数据。例如,数据质量元数据指的是关于数据资源(数据库、数据湖等)质量的信息。元数据允许您以对用例有独特意义的方式组织和理解数据,同时保持数据的一致性和准确性。
这一级别的异常处理“一般”数据,是最接近数据本身的异常。这些是关于数据的异常,而不是数据中的异常(然而,它们仍然可以表示数据中的问题)。当数据质量出现意外下降时,就会出现这种情况;当一个数据集/点通常以一种方式标记,但已经以另一种方式标记;或者在提取关于您所存储的数据的数据时,缺少一定数量的记录、记录太少或记录太多,以及发生任何其他意外情况。
事务性数据异常
从元数据转向更接近特定数据的地方,我们到达了中间层——事务性数据。我们称之为中间层,因为您正在处理来自实际数据的值,但通过聚合的镜头(即,每五天或每五分钟一次)。交易数据通常包含某种形式的货币交易,因为分析此类数据的能力非常有用。例如,如果您有每五分钟的销售汇总,您可以使用它来确定最繁忙的时间,是否值得在晚上8点后营业等等。
在这一水平上出现的异常情况可能是在一年中销售较慢的某周出现了意外的销售增长,购物假期的销售额与一周中正常日子的销售额相似,或者一个分支机构的业绩在繁忙的月份下降得异常低,等等。
记录级别的异常
在记录级别,异常检测标记数据集中可疑的特定值。如果其中一个数据点缺失、不完整、不一致或不正确,则可以将这些值标记为异常。
我们的介绍是记录级异常的一个很好的例子。数据集中的一个值(性别)是意外的,并且与系统中的其他值不协调。这只是一行信息,是包含患者年龄、既往病史、身高、体重等更大信息集的一部分。
记录级别的异常检测逐行探索每个表和列中的数据集,寻找任何不一致之处。它可以揭示数据收集、聚合或处理中的问题。
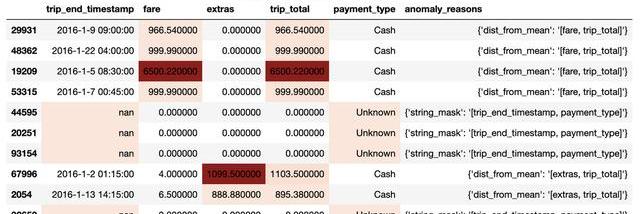
异常检测类型
现在我们了解了不同类型的异常,我们可以进入不同的方法来检测它们。一种方法侧重于将时间作为数据的主要上下文,而另一种方法侧重于在正常行为的上下文中发现异常。这两种类型的异常检测被称为时间相关和时间无关。
时变异常检测
依赖于时间的数据会随着时间的推移而演变(考虑一下我们的事务性数据示例),因此了解何时捕获值、何时输入值、多个条目以何种顺序到达等非常重要。通常,用户将这些数据分组(聚合)在一起(例如,每小时或每天),并在组级别上寻找异常或趋势,根据上下文发现异常值。
例如,当您有每日数据(即每天记录一次)时,您可以预期一些季节性。换句话说,周一的期望值可能与周二不同。因此,不同的值在不同的日子可能是异常的。此外,这些数据经常在较长时期内发生变化。这可以用数据的趋势或数据的漂移变化来表示。所有这些模式都需要时变异常检测算法来捕获。
非时变异常检测
任何没有时间维度的数据都可以被认为是“时间无关的”。换句话说,数据是什么时候创建的,输入到系统中,数据到达的顺序等等都不重要。只有实际值才重要。因此,算法只需要了解期望值是什么,或者更好的是,将它们放入“正态聚类”中。
这些异常与主数据(相对于事务数据)更相关:客户记录、产品数据、参考数据和其他“静态数据”。
结论
总之,异常检测算法允许您发现数据中不需要或意外的值,而无需指定规则和标准。它对您的数据集进行快照,并通过将新数据与过去关于相同或类似数据集发现的模式进行比较来识别异常。
至于对异常检测工具可以做什么的期望:
无论这些异常发生在较高的级别(如元数据)还是接近实际数据本身(如记录级别异常),您的异常检测服务都需要能够发现它们。
要应用于所有类型的数据,既需要时变异常检测,也需要时变异常检测。
您的服务还必须能够处理不同的数据类型,易于使用和适应,并在将值标记为异常时提供可用的解释。
异常检测领域持续增长和发展。AI/ML正在数据管理领域得到更广泛的采用和实现。我们可以预期异常检测将变得越来越主动,而不是被动。这些工具将能够在数据进入下游系统之前发现有问题的数据,从而造成损害。
异常检测很有价值,因为它通常会揭示数据之外的潜在问题,例如物联网设备中的缺陷机器、网络中的黑客企图、数据合并中的基础设施故障或不准确的医疗检查。这些问题通常很难预测,因此很难编写DQ规则。因此,基于AI/ml的异常检测是发现这些异常的最佳方法。
网传“6月1日香港居民自由买卖加密货币将完全合法”后,香港概念币直接起飞了。 加之上周“ConfluxNetwork宣布将与中国电信合作,在香港试行支持区块链的SIM卡”,Conflux币价涨势.
1900/1/1 0:00:00DeFi近年来发展得如火如荼,来自世界各地的币圈投资者纷纷选择入局DeFi,与之相关的项目板块也不断涌现,DeFi聚合器就是其中之一.
1900/1/1 0:00:00中非共和国是非洲中部的一个内陆国家。这是个领土面积比乌克兰还大的国家,62万平方公里的国土上只生活着400多万人口,是世界上人口密度最低的十二个国家之一.
1900/1/1 0:00:00TerraUST的崩溃给去中心化的稳定币生态系统蒙上了一层阴影。然而,DAI、FRAX、LUSD和sUSD却经历了加密货币史上最动荡时期而存活下来.
1900/1/1 0:00:00亚利桑那州立大学计算机科学专业分布式和多处理器操作系统课程介绍本课程将教授分布式系统的基本概念和原理以及开发分布式系统的实践技能。首先,本课程提供了对分布式系统及其设计目标和系统类型的初步探索.
1900/1/1 0:00:00酣睡的人有同一种幸福的模样,睡不好的人却各有各的不幸。《中国睡眠研究报告》显示,中国人的平均睡眠时长从2012年的8.5小时降至2021年的7.06小时.
1900/1/1 0:00:00