导读
首先问大家一个小问题?区块链的账本数据存储格式主要是什么类型的?
相信聪明的你一定知道是Key-Value类型存储。
下一个问题,这些Key-Value数据在底层数据库如何高效组织?
答案就是我们本期介绍的内容:LSM。
LSM是一种被广泛采用的持久化Key-Value存储方案,如LevelDB,RocksDB,Cassandra等数据库均采用LSM作为其底层存储引擎。
据公开数据调研,LSM是当前市面上写密集应用的最佳解决方案,也是区块链领域被应用最多的一种存储模式,今天我们将对LSM基本概念和性能进行介绍和分析。
LSM-Tree背景:追本溯源
LSM-Tree的设计思想来自于一个计算机领域一个老生常谈的话题——对存储介质的顺序操作效率远高于随机操作。
如图1所示,对磁盘的顺序操作甚至可以快过对内存的随机操作,而对同一类磁盘,其顺序操作的速度比随机操作高出三个数量级以上,因此我们可以得出一个非常直观的结论:应当充分利用顺序读写而尽可能避免随机读写。

Figure1Randomaccessvs.Sequentialaccess
辽宁省“十四五”规划:利用区块链等技术 建设面向消费品行业的服务平台:2月1日,辽宁省政府新闻办召开贯彻省“两会”精神新闻发布会。会议指出,“十四五”期间,辽宁省工信厅将加强新一代信息技术与制造业融合,用数字经济为优势产业赋能增效,打造一批典型应用场景,布局一批智能工厂、智能车间,加快培育网络化协同、智能化制造等新模式新业态。利用区块链等技术,建设面向消费品行业的服务平台,扩大个性化定制产品占比。(辽宁日报)[2021/2/2 18:41:19]
考虑到这一点,如果我们想尽可能提高写操作的吞吐量,那么最好的方法一定是不断地将数据追加到文件末尾,该方法可将写入吞吐量提高至磁盘的理论水平,然而也有显而易见的弊端,即读效率极低,我们称这种数据更新是非原地的,与之相对的是原地更新。
为了提高读取效率,一种常用的方法是增加索引信息,如B+树,ISAM等,对这类数据结构进行数据的更新是原地进行的,这将不可避免地引入随机IO。
LSM-Tree与传统多叉树的数据组织形式完全不同,可以认为LSM-Tree是完全以磁盘为中心的一种数据结构,其只需要少量的内存来提升效率,而可以尽可能地通过上文提到的Journaling方式来提高写入吞吐量。当然,其读取效率会稍逊于B+树。
LSM-Tree数据结构:抽丝剥茧
动态 | 顺丰利用大数据和区块链技术 实现甘孜松茸的全程追溯:据环球财富网消息,7月10日,顺丰甘孜松茸预处理中心揭牌仪式在四川雅江举办。据悉,顺丰基于其大数据及区块链技术,在松茸上实现了全程可追溯,打造松茸全产业链质量与食品安全管理系统,使用智能设备搭载智能系统,结合特征码追溯等方式,记录每一棵松茸的采摘人员、采摘地区、生长周期、装箱时间、分拣时间等,让天生天养的松茸实现了数据沉淀与管理。[2019/7/11]
图2展示了LSM-Tree的理论模型(a)和一种实现方式(b)。LSM-Tree是一种层级的数据结构,包含一层空间占用较小的内存结构以及多层磁盘结构,每一层磁盘结构的空间上限呈指数增长,如在LevelDB中该系数默认为10。
Figure2LSM与其LevelDB实现
对于LSM-Tree的数据插入或更新,首先会被缓存在内存中,这部分数据往往由一颗排序树进行组织。
当缓存达到预设上限,则会将内存中的数据以有序的方式写入磁盘,我们称这样的有序列为一个SortedRun,简称为Run。
随着写入操作的不断进行,L0层会堆积越来越多的Run,且显然不同的Run之前可能存在重叠部分,此时进行某一条数据的查询将无法准确判断该数据存在于哪个Run中,因此最坏情况下需要进行等同于L0层Run数量的I/O。
为了解决该问题,当某一层的Run数目或大小到达某一阈值后,LSM-Tree会进行后台的归并排序,并将排序结果输出至下一层,我们将一次归并排序称为Compaction。如同B+树的分裂一样,Compaction是LSM-Tree维持相对稳定读写效率的核心机制,我们将会在下文详细介绍两种不同的Compaction策略。
动态 | 禅城将借力区块链等信息技术 对人才服务再升级:据广州日报大洋网报道,禅城将借力区块链等信息技术,对人才服务再升级。区人社部门相关负责人介绍,禅城将重构人才服务办理流程,力争人才公寓、技能人才子女入学、毕业生就业报到、人才资格认定等37项业务实现“零跑腿”办理。[2019/1/18]
另外值得一提的是,无论是从内存到磁盘的写入,还是磁盘中不断进行的Compaction,都是对磁盘的顺序I/O,这就是LSM拥有更高写入吞吐量的原因。
Levelingvs.Tiering:一读一写,不分伯仲
LSM-Tree的Compaction策略可以分为Leveling和Tiering两种,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,称采用Leveling策略的的LSM-Tree为LeveledLSM-Tree,采用Tiering的LSM-Tree为TieredLSM-Tree,如图3所示。

Figure3两种Compaction策略对比
▲Leveling
简而言之,Tiering是写友好型的策略,而Leveling是读友好型的策略。在Leveling中,除了L0的每一层最多只能有一个Run,如图3右侧所示,当在L0插入13时,触发了L0层的Compaction,此时会对Run-L0与下层Run-L1进行一次归并排序,归并结果写入L1,此时又触发了L1的Compaction,此时会对Run-L1与下层Run-L2进行归并排序,归并结果写入L2。
声音 | “贵州信用云”利用区块链等技术 实现对信用主体的精准信用画像:据人民日报海外版报道,在今年中国城市信用建设高峰论坛上,贵州省信息中心副主任唐云评价“贵州信用云”的建设称:“人在干,云在算,授不授信数据说了算”。据悉,“贵州信用云” 是以云计算资源为支撑,把大数据、区块链、人工智能等技术应用于信用上,实现对信用主体的精准信用画像。[2018/7/17]
▲Tiering
反观Tiering在进行Compaction时并不会主动与下层的Run进行归并,而只会对发生Compaction的那一层的若干个Run进行归并排序,这也是Tiering的一层会存在多个Run的原因。
▲对比分析
相比而言,Leveling方式进行得更加贪婪,进行了更多的磁盘I/O,维持了更高的读效率,而Tiering则相正好反。
本节我们将对LSM-Tree的设计空间进行更加形式化的分析。
LSM层数

布隆过滤器
LSM-Tree应用布隆过滤器来加速查找,LSM-Tree为每个Run设置一个布隆过滤器,在通过I/O查询某个Run之前,首先通过布隆过滤器判断待查询的数据是否存在于该Run,若布隆过滤器返回Negative,则可断言不存在,直接跳到下个Run进行查询,从而节省了一次I/O;而若布隆过滤器返回Positive,则仍不能确定数据是否存在,需要消耗一次I/O去查询该Run,若成功查询到数据,则终止查找,否则继续查找下一个Run,我们称后者为假阳现象,布隆过滤器的过高的假阳率会严重影响读性能,使得花费在布隆过滤器上的内存形同虚设。限于篇幅本文不对布隆过滤器做更多的介绍,直接给出FPR的计算公式,为公式2.
Chanticleer部署区块链技术 盘前上涨109%: 2018年1月2日,Mobient控股公司(MFON)是智能和个性化营销屡获殊荣的平台制造商,以及Chanticleer控股公司(BURG)几家快速休闲餐厅品牌的运营商今天宣布,计划使用MobivityMind这一区块链架构的跨品牌商业和客户沟通平台,为客户忠诚度和奖励计划提供动力,此举让Chanticleer的股票盘前上涨109%。[2018/1/3]
其中是为布隆过滤器设置的内存大小,为每个Run中的数据总数。读写I/O
考虑读写操作的最坏场景,对于读操作,认为其最坏场景是空读,即遍历每一层的每个Run,最后发现所读数据并不存在;对于写操作,认为其最坏场景是一条数据的写入会导致每一层发生一次Compaction。
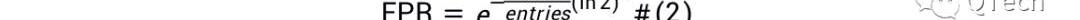
核心理念:基于场景化的设计空间
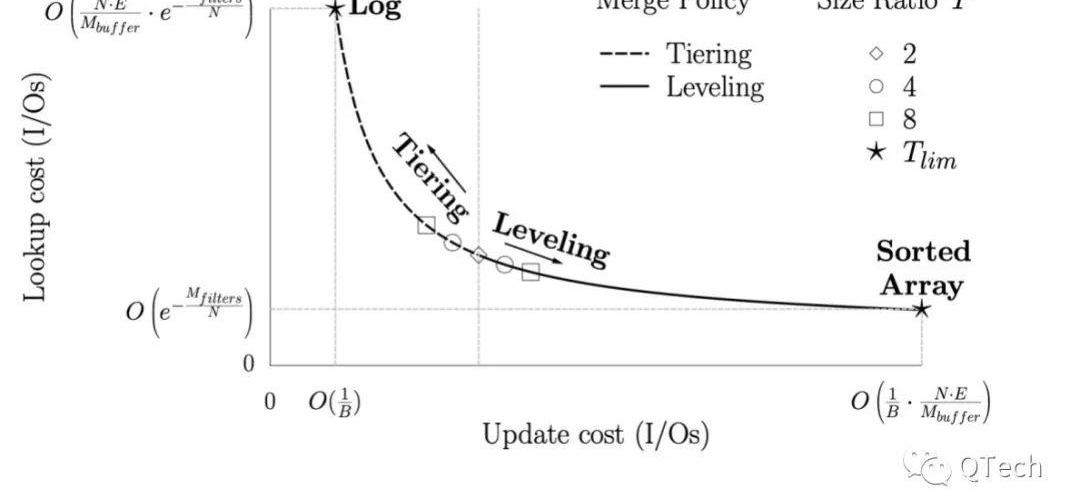
基于以上分析,我们可以得出如图4所示的LSM-Tree可基于场景化的设计空间。
简而言之,LSM-Tree的设计空间是:在极端优化写的日志方式与极端优化读的有序列表方式之间的折中,折中策略取决于场景,折中方式可以对以下参数进行调整:

当Level间放大比例时,两种Compaction策略的读写开销是一致的,而随着T的不断增加,Leveling和Tiering方式的读开销分别提高/减少。
当T达到上限时,前者只有一层,且一层中只有一个Run,因此其读开销到达最低,即最坏情况下只需要一次I/O,而每次写入都会触发整层的Compaction;
而对于后者当T到达上限时,也只有一层,但是一层中存在:

因此读开销达到最高,而写操作不会触发任何的Compaction,因此写开销达到最低。
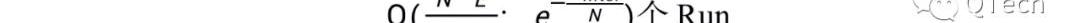
Figure4LSM由日志到有序列的设计空间
事实上,基于图4及上文的分析可以进行对LSM-Tree的性能进一步的优化,如文献对每一层的布隆过滤器大小进行动态调整,以充分优化内存分配并降低FPR来提高读取效率;文献提出“LazyLeveling”方式来自适应的选择Compaction策略等。
限于篇幅本文不再对这些优化思路进行介绍,感兴趣的读者可以自行查阅文献。
小结
LSM-Tree提供了相当高的写性能、空间利用率以及非常灵活的配置项可供调优,其仍然是适合区块链应用的最佳存储引擎之一。
本文对LSM-Tree从设计思想、数据结构、两种Compaction策略几个角度进行了由浅入深地介绍,限于篇幅,基于本文之上的对LSM-Tree的调优方法将会在后续文章中介绍。
作者简介叶晨宇来自趣链科技基础平台部,区块链账本存储研究小组
参考文献
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
作者:蒋海波,PANews因为MEME和BRC-20代币的炒作,进入5月份以来,以太坊和比特币网络中的Gas费连续创下短期新高.
1900/1/1 0:00:00原文作者:MooMs,编译:Odaily星球日报?Mia?NEXProtocol?建设者?MooMs?长期追踪Web3“聪明钱”的流向,并试图提前发现下个行业趋势.
1900/1/1 0:00:00作者:RachelWolfson编译:陈一鸣链新人们期待已久的对以太坊网络的安全和可扩展性升级,已经按计划于12月1日启动,这对以太坊社区来说,是一个巨大的里程碑.
1900/1/1 0:00:00电动汽车制造商特斯拉周一公布,特斯拉在2021年第一季度出售了其持有的部分比特币,价值2.72亿美元.
1900/1/1 0:00:00注,此文是对AxieInfinity最初奖学金计划的创建者AK的采访,原作者为archeus-nft,以下为全文编译.
1900/1/1 0:00:00Finoverse很高兴地宣布即将举办RadicalFinance——一场针对希望深入研究Web3和AI领域的金融专业人士的独家盛会,大会形式为邀请参与.
1900/1/1 0:00:00