来源:新智元
开源先锋StabilityAI一天扔了两枚重磅炸弹:发布史上首个开源RLHF大语言模型,以及像素级图像模型DeepFloydIF。开源社区狂喜!
最近,大名鼎鼎的StableDiffusion背后的公司,一连整了两个大活。
首先,StabilityAI重磅发布了世上首个基于RLHF的开源LLM聊天机器人——StableVicuna。

StableVicuna基于Vicuna-13B模型实现,是第一个使用人类反馈训练的大规模开源聊天机器人。
有网友经过实测后表示,StableVicuna就是目前当之无愧的13BLLM之王!
对此,1xexited创始人表示,这可以看作是自ChatGPT推出以来的第二个里程碑。

另外,StabilityAI发布了开源模型DeepFloydIF,这个文本到图像的级联像素扩散模型功能超强,可以巧妙地把文本集成到图像中。

这个模型的革命性意义在于,它一连解决了文生图领域的两大难题:正确生成文字,正确理解空间关系!
秉持着开源的一贯传统,DeepFloydIF在以后会完全开源。
StailibityAI,果然是开源界当之无愧的扛把子。

StableVicuna
世上首个开源RLHFLLM聊天机器人StableVicuna,由StabilityAI震撼发布!

EPNS宣布Rockstars of EPNS NFT已在OpenSea上线:12月11日消息,以太坊推送服务(EPNS)发推称,其NFT收藏品“Rockstars of EPNS”现已在OpenSea上线。
据此前4月份报道,以太坊推送服务(EPNS)宣布将发行NFT,接下来的一年内每周赠送给社区成员。该系列NFT被称为ROCKSTARS,由印度艺术家创作,共100幅插画,将分为两个阶段发布,最初的分发以及后续的每周分发。团队表示,每周一他们会将一份EPNS的NFT赠送给一位社区内的粉丝、支持者或传播者。初期分发的48个将会赠送给项目的顾问或者提供帮助的人,后续团队会在推特上联系安排。[2021/12/12 7:33:30]
一位Youtube主播对StableVicuna进行了实测,StableVicuna在每一次测试中,都击败了前任王者Vicuna。

所以这位Youtuber激动地喊出:StableVicuna就是目前最强大的13BLLM模型,是当之无愧的LLM模型之王!


StableVicuna基于小羊驼Vicuna-13B模型实现,是Vicuna-13B的进一步指令微调和RLHF训练的版本。
而Vicuna-13B是LLaMA-13B的一个指令微调模型。

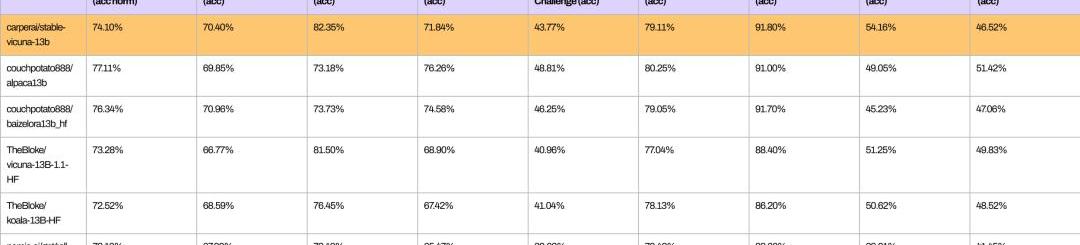
从以下基准测试可以看出,StableVicuna与类似规模的开源聊天机器人在整体性能上的比较。
Instagram高管宣布与NBA Top Shot合作推出AR版NFT:Instagram运动合作部门负责人WillYoder发推称,已与DapperLabs及NBA达成合作,将在Instagram上共同推出AR版的NBATopShot。目前已有6枚季后赛主题的AR版NBA Top Shot可供观看。[2021/7/12 0:45:24]
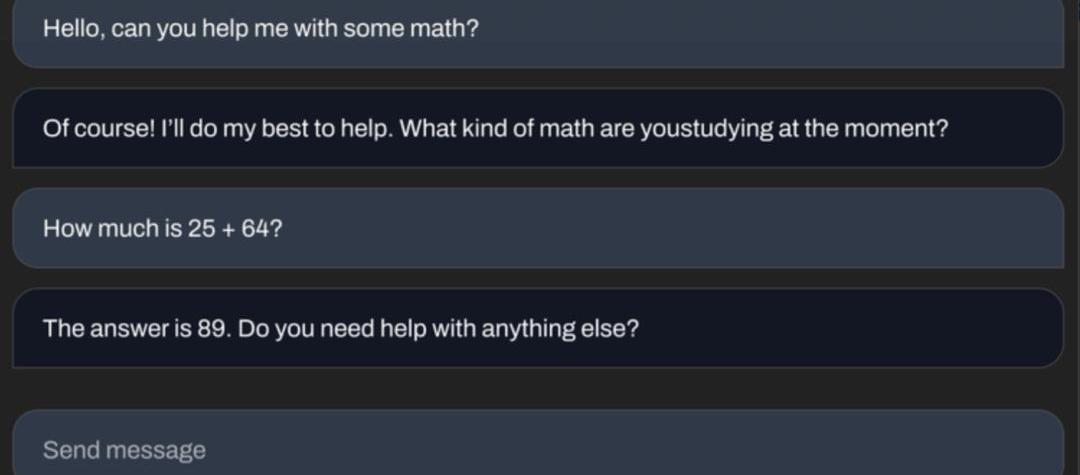
StableVicuna可以做基础数学题。
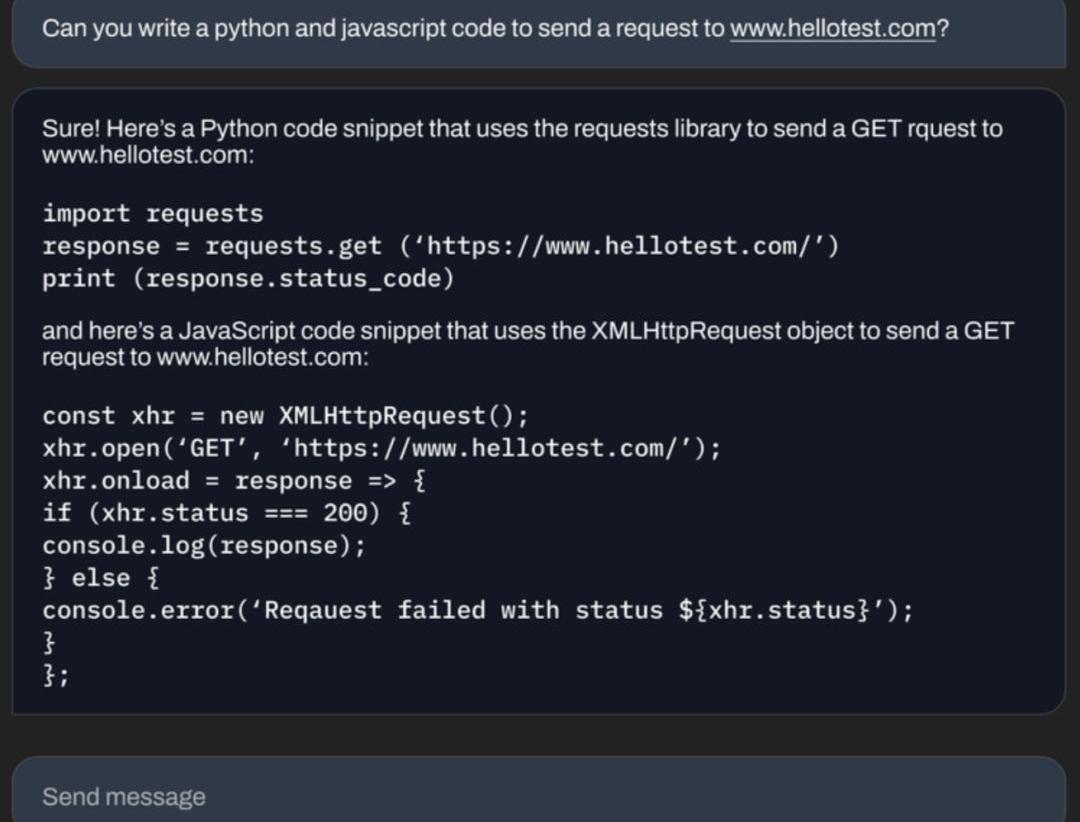
可以写代码。
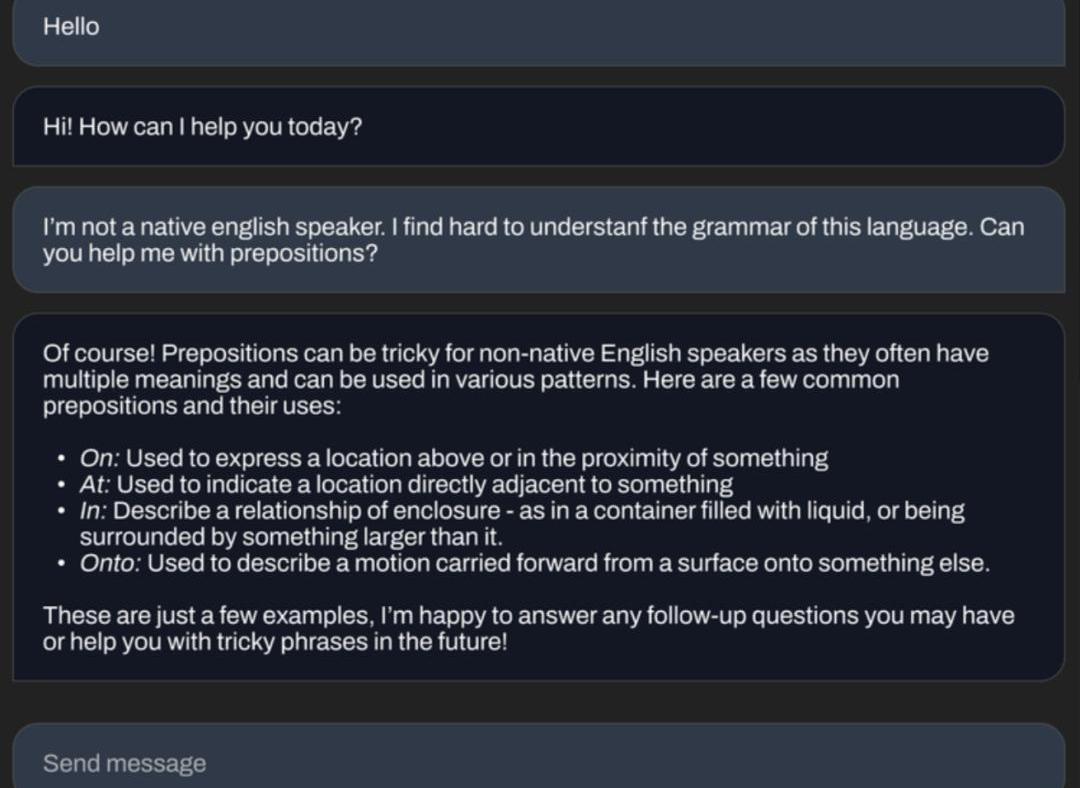
还能为你讲解语法知识。
开源聊天机器人平替狂潮
StabilityAI想做这样一个开源的聊天机器人,当然也是受了此前LLaMa权重泄露引爆的ChatGPT平替狂潮的影响。
从去年春天Character.ai的聊天机器人,到后来的ChatGPT和Bard,都引发了大家对开源平替的强烈兴趣。
这些聊天模型的成功,基本都归功于这两种训练范式:指令微调和人类反馈强化学习(RLHF)。

这期间,开发者一直在努力构建开源框架帮助训练这些模型,比如trlX、trl、DeepSpeedChat和ColossalAI等,然而,却并没有一个开源模型,能够同时应用指令微调和RLHF。
大多数模型都是在没有RLHF的情况下进行指令微调的,因为这个过程十分复杂。
最近,OpenAssistant、Anthropic和Stanford都开始向公众提供RLHF数据集。
StabilityAI把这些数据集与trlX提供的RLHF相结合,就得到了史上第一个大规模指令微调和RLHF模型——StableVicuna。
BKEX Global Staking锁仓挖矿将开启YFII矿池:据BKEX Global公告,BKEX Global Staking锁仓挖矿将于2020年10月21日20:00(UTC+8)开启YFII矿池,收益发放时间为每日16:00~18:00。
Staking锁仓挖矿指在特定加密货币钱包中存入代币从而支持该区块链网络运营的一种行为,权益证明(PoS)机制下该质押行为会得到代币奖励。用户通过锁定一定期限数字资产,获得收益,锁仓期间不支持提现和交易(可随时解锁锁仓资产),适用于长期持币的用户。[2020/10/21]
训练过程
为了实现StableVicuna的强大性能,研究者利用Vicuna作为基础模型,并遵循了一种典型的三级RLHF管线。
Vicuna在130亿参数LLaMA模型的基础上,使用Alpaca进行调整后得到的。

他们混合了三个数据集,训练出具有监督微调(SFT)的Vicuna基础模型:
OpenAssistantConversationsDataset(OASST1),一个人工生成的、人工注释的助理式对话语料库,包含161,443条消息,分布在66,497个对话树中,使用35种不同的语言;
GPT4AllPromptGenerations,由GPT-3.5Turbo生成的437,605个提示和响应的数据集;
Alpaca,这是由OpenAI的text-davinci-003引擎生成,包含52,000条指令和演示的数据集。
研究者使用trlx,训练了一个奖励模型。在以下这些RLHF偏好数据集上,研究者得到了SFT模型,这是奖励模型的基础。
OpenAssistantConversationsDataset(OASST1),包含7213个偏好样本;
AnthropicHH-RLHF,一个关于AI助手有用性和无害性的偏好数据集,包含160,800个人类标签;
斯坦福人类偏好(SHP),这是一个数据集,包含348,718个人类对各种不同回答的集体偏好,包括18个从烹饪到哲学的不同学科领域。
最后,研究者使用了trlX,进行近端策略优化(ProximalPolicyOptimization,PPO)强化学习,对SFT模型进行了RLHF训练,然后,StableVicuna就诞生了!

据StabilityAI称,会进一步开发StableVicuna,并且会很快在Discord上推出。
稳定币聚合协议mStable推出协议代币Meta(MTA):稳定币聚合协议mStable宣布推出协议代币Meta(MTA),MTA有三个主要功能:1)作为再担保(保险)的最终来源;2)协调mStable的去中心化治理;3)激励mStable的资产流动性、效用和社区治理。目前仅功能3可用,功能1和功能1将在协议第二阶段启用。首个MTA生态系统奖励池已在Balancer上运行,通过向Balancer的mUSD/USDC流动池做贡献,每周可获得50,000MTA的份额,以及向该流动池支付的所有BAL奖励。[2020/6/27]
另外,StabilityAI还计划给StableVicuna一个聊天界面,目前正在开发中。
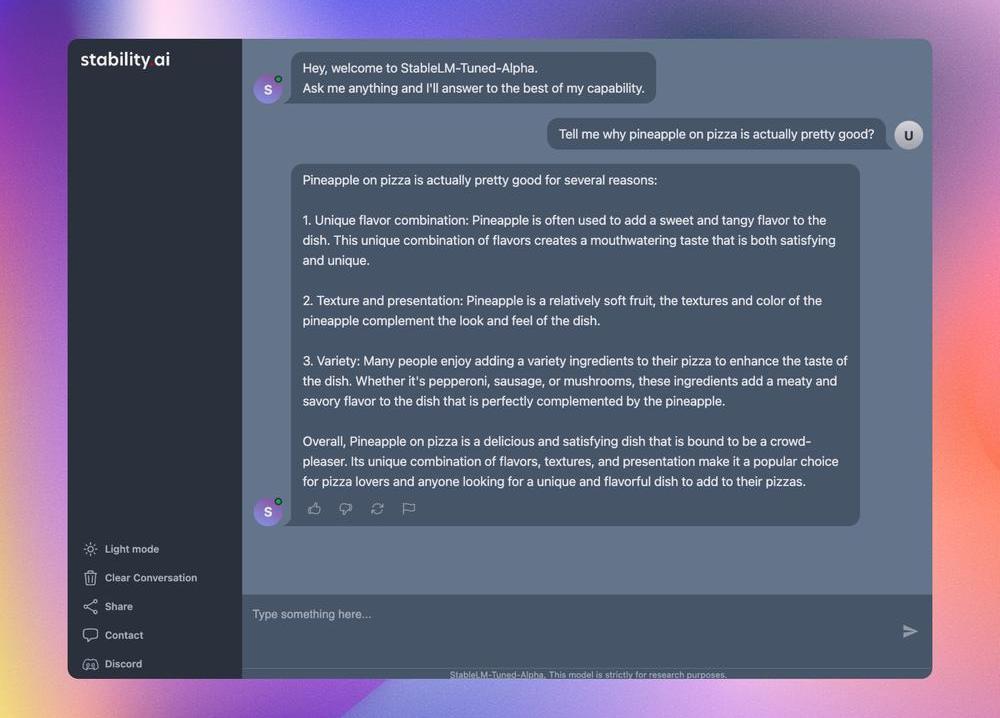
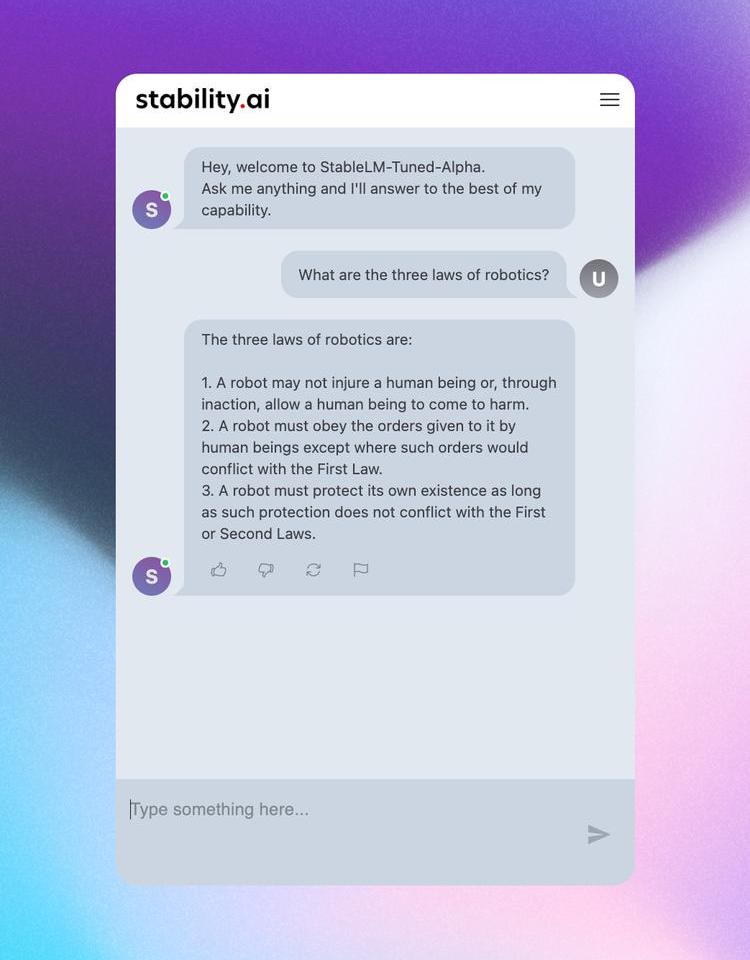
相关演示已经可以在HuggingFace上查看了,开发者也可以在HuggingFace上下载模型的权重,作为原始LLaMA模型的增量。
但如果想使用StableVicuna,还需要获得原始LLaMA模型的访问权限。
获得权重增量和LLaMA权重后,使用GitHub存储库中提供的脚本将它们组合起来,就能得到StableVicuna-13B了。不过,也是不允许商用的。
DeepFloydIF
在同一时间,StabilityAI还放出了一个大动作。
你敢信,AI一直无法正确生成文字这个老大难问题,竟然被解决了?
没错,下面这张「完美」的招牌,就是由StabilityAI全新推出的开源图像生成模型——DeepFloydIF制作的。

除此之外,DeepFloydIF还能够生成正确的空间关系。

模型刚一发布,网友们已经玩疯了:
动态 | Globitex利用Bitfury Crystal平台施行反合规措施:致力于提供加密业务的金融科技公司Globitex宣布与Bitfury Group旗下的Crystal Blockchain达成合作。Crystal Blockchain通过Bitfury Crystal平台为客户提供反合规和安全措施。这项合作是在欧盟第五项反指令(5AMLD)出台后展开的,旨在帮助Globitex识别通过混币机进行的可疑交易、被盗资金和加密货币。(The Paypers)[2020/2/26]

prompt:Robotholdinganeonsignthatsays"Icanspell".



不过,对于prompt中没有明确说明的文字,DeepFloydIF大概率还是会出错。

prompt:AneonsignofanAmericanmotelatnightwiththesignjavilop

官方演示



顺便一提,在硬件的需求上,如果想要实现模型所能支持的最大1,024x1,024像素输出,建议使用24GB的显存;如果只要256x256像素,16GB的显存即可。
是的,RTX306016G就能跑。
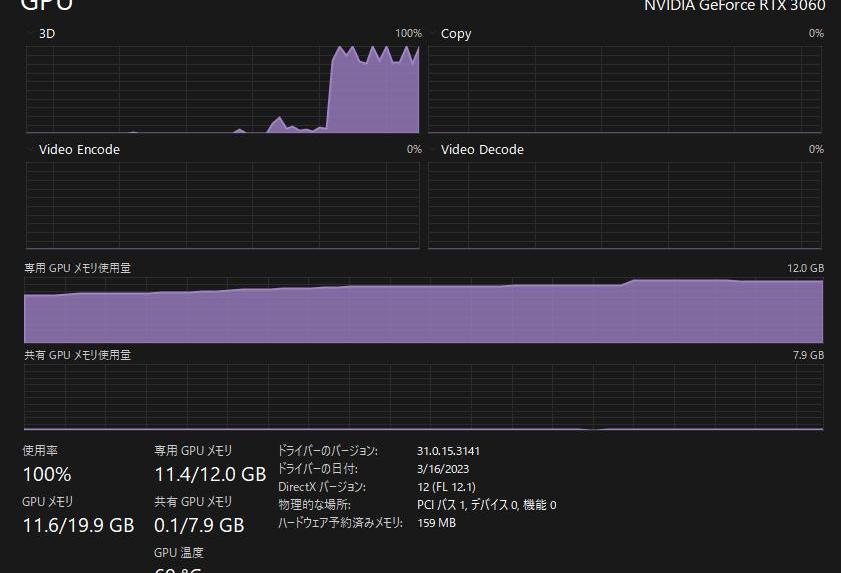
代码实现:https://gist.github.com/Stella2211/ab17625d63aa03e38d82ddc8c1aae151
开源版谷歌Imagen
2022年5月,谷歌高调发布了自家的图像生成模型Imagen。
根据官方演示的效果,Imagen不仅在质量上完胜OpenAI最强的DALL-E2,更重要的是——它能够正确地生成文本。
迄今为止,没有任何一个开源模型能够稳定地实现这一功能。

与其他生成式AI模型一样,Imagen也依赖于一个冻结的文本编码器:先将文本提示转换为嵌入,然后由扩散模型解码成图像。但不同的是,Imagen并没有使用多模态训练的CLIP,而是使用了大型T5-XXL语言模型。
这次,StabilityAI推出的DeepFloydIF复刻的正是这一架构。
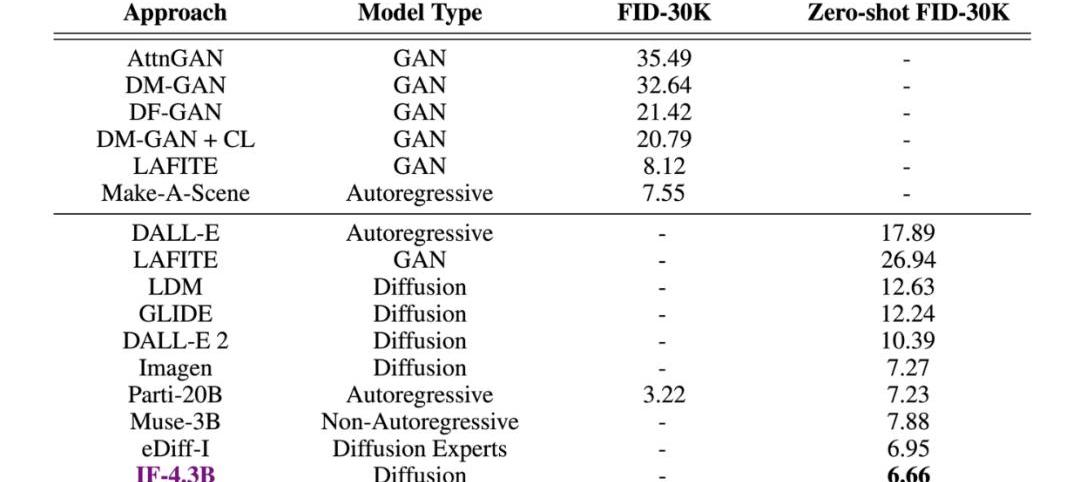
甚至在测试中,DeepFloydIF凭借着COCO数据集上6.66的zero-shotFID分数,直接超越了谷歌的Imagen,以及一众竞品。
下一代图像生成AI模型
具体来说,DeepFloydIF是一个模块化、级联的像素扩散模型。
模块化:
DeepFloydIF由几个神经模块组成,它们在一个架构中相互协同工作。
级联:
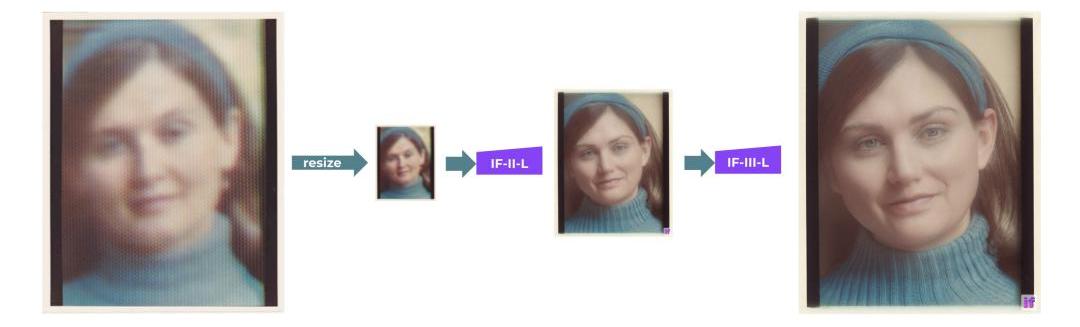
DeepFloydIF以多个模型级联的方式实现高分辨率输出:首先生成一个低分辨率的样本,然后通过连续的超分辨率模型进行上采样,最终得到高分辨率图像。
扩散:
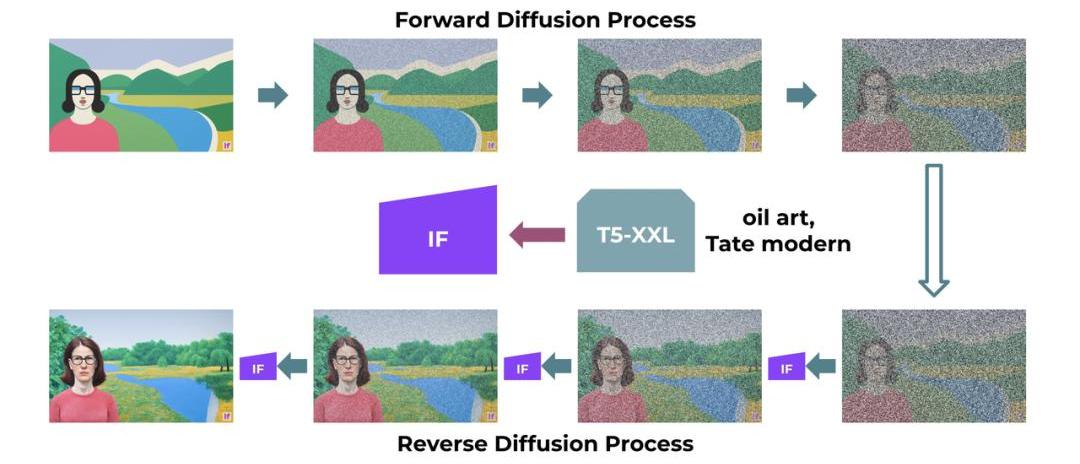
DeepFloydIF的基本模型和超分辨率模型都是扩散模型,其中使用马尔可夫链的步骤将随机噪声注入到数据中,然后反转该过程从噪声中生成新的数据样本。
像素:
DeepFloydIF在像素空间工作。与潜在扩散模型不同,扩散是在像素级别实现的,其中使用潜在表征。
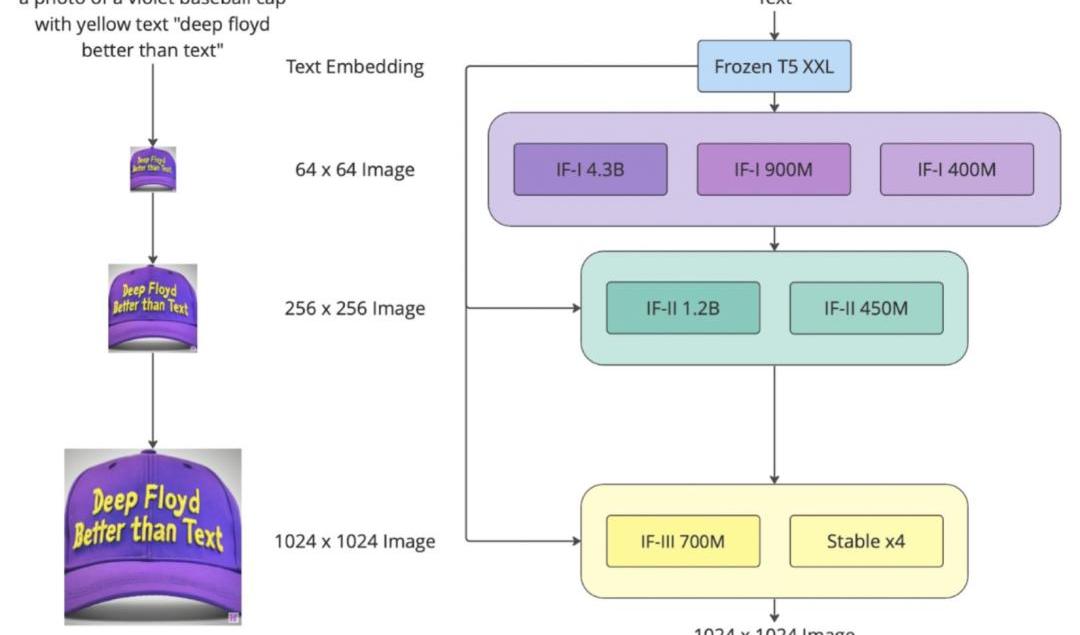
上面这个流程图展示的就是,DeepFloydIF三个阶段的性能:
阶段1:
基本扩散模型将定性文本转换为64x64图像。DeepFloyd团队已经训练了三个版本的基本模型,每个版本都有不同的参数:IF-I400M、IF-I900M和IF-I4.3B。
阶段2:
为了「放大」图像,团队将两个文本条件超分辨率模型应用于基本模型的输出。其中之一将64x64图像放大到256x256图像。同样,这个模型也有几个版本:IF-II400M和IF-II1.2B。
阶段3:
应用第二个超分辨率扩散模型,生成生动的1024x1024图像。最后的第三阶段模型IF-III拥有700M参数。
值得注意的是,团队还没有正式发布第三阶段的模型,但DeepFloydIF的模块化特性让我们可以使用其他上采样模型——如StableDiffusionx4Upscaler。
团队表示,这项工作展示了更大的UNet架构在级联扩散模型的第一阶段的潜力,从而为文本到图像合成展示了充满希望的未来。


数据集训练
DeepFloydIF是在一个定制的高质量LAION-A数据集上进行训练的,该数据集包含10亿对。
LAION-A是LAION-5B数据集英文部分的一个子集,基于相似度哈希去重后获得,对原始数据集进行了额外的清理和修改。DeepFloyd的定制过滤器用于删除水印、NSFW和其他不适当的内容。
目前,DeepFloydIF模型的许可仅限于非商业目的的研究,在完成反馈的收集之后,DeepFloyd和StabilityAI团队将发布一个完全免费的商业版本。
参考资料:
https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
https://stability.ai/blog/deepfloyd-if-text-to-image-model
原文作者:Ailsa多链生态的繁荣催生了用户对跨链的需求。链与链之间的跨链交互的日益增加,但与此同时跨链安全事件频频发声,跨链安全成为市场关注的焦点.
1900/1/1 0:00:00随着经济发展和社会进步,市场对区块链技术和元宇宙的需求最近一直在上升。企业越来越热衷于将自己的品牌带入Web3生态,阿里巴巴云已经开始帮助其客户进行转型.
1900/1/1 0:00:00brc-20相关生态愈发繁荣,因此我们将目光转到brc-20生态的推动者@domodata,揭开这位Ordinals协议背后“V神”的神秘面纱.
1900/1/1 0:00:00来源:时尚座驾car编辑/天择文、图/忘书随着科幻IP《三体》的大火,汇集了创新、变革和前瞻科技的“元宇宙”,再一次成为了热门话题.
1900/1/1 0:00:00摘要:据阿尔法工场研究院报道,在今年爆发的AI大战中,微软、谷歌、亚马逊等各个大厂,都纷纷使出了自己的浑身解数,渴望在未来的赛道中抢占先机.
1900/1/1 0:00:00自Ordinals协议将BTCNFT带火之后,BRC-20又成为了用户、CEX?争抢布局的新赛道。这些新协议的出现让一向「古板」的比特币链又重新焕发生机.
1900/1/1 0:00:00