ChatGPT引爆的AI热潮也“烧到了”金融圈,彭博社重磅发布为金融界打造的大型语言模型——BloombergGPT。
3月30日,根据彭博社最新发布的报告显示,其构建迄今为止最大的特定领域数据集,并训练了专门用于金融领域的LLM,开发了拥有500亿参数的语言模型——BloombergGPT。
报告显示,该模型依托彭博社的大量金融数据源,构建了一个3630亿个标签的数据集,支持金融行业内的各类任务。该模型在金融任务上的表现远超过现有模型,且在通用场景上的表现与现有模型也能一较高下。
一般来说,在NLP领域,参数数量和复杂程度之间具有正相关性,GPT-3.5模型的参数量为2000亿,GPT-3的参数量为1750亿。

加密教育家:以太坊将在比特币之前成为全球金融储备资产:加密教育家Omar Bham(crypt0snews)今日发推称,如果央行需要持有以太坊来转移公共区块链上的代币化证券,我可以看到以太坊在比特币之前成为全球金融储备资产。事实上这已经在发生了。[2020/5/31]
关于BloombergGPT
报告指出,研究人员利用彭博社现有的数据,对资源进行创建、收集和整理,通过构建迄今为止最大的特定领域数据集来完成BloomberGPT,并基于通用和金融业务的场景进行混合模型训练:
彭博社主要是一家金融数据公司,数据分析师在公司成立的四十年的时间里收集了大量的金融文件,拥有广泛的金融数据档案,涵盖了一系列的主题。
我们将这些数据添加到公共数据集中,以创建一个拥有超过7000亿个标签的大型训练语料库。
使用这个训练语料库的一部分,我们训练了一个具有彭博风格的,达500亿参数的模型,该模型是根据Hoffmann和LeScao等人的指导方针设计,基于通用和金融业务的场景进行混合模型训练。
声音 | 信雅达董事长耿俊岭:公司致力于区块链与金融数据的结合应用:11月5日消息,浙江辖区上市公司2019年投资者集体接待日活动周二下午在浙江杭州举办。信雅达董事长耿俊岭表示,区块链主要应用在金融的基础建设上,信雅达目前在做的工作就是把区块链的技术跟金融数据结合起来,重点是做好区块链的数字信用,帮助这些数据更安全、更有效、更协同地在多主体之间去运用。[2019/11/5]
结果表明,我们的混合训练方法使我们的模型在金融任务上的表现大大超过了现有的模型,而在通用场景上的表现则与之相当甚至优于现有模型。

声音 | 国家金融研究院院长朱民:我们对Libra的出世不应该掉以轻心:据腾讯财经消息,7月1日,2019年世界经济论坛新领军者年会(夏季达沃斯)在辽宁大连举行。在“塑造中国未来金融业”的分论坛上,国家金融研究院院长朱民谈到了Facebook的数字货币Libra。朱民表示,很难说Libra是一个支付宝,因为支付宝是一个支付中介,而Libra是从支付开始,有储备有本金和债券做抵押物,有一篮子货币作为标注和定价的,它的核心概念是货币。第二,Libra的核心概念是跨境。第三,Libra是把央行要考虑的政策和商业银行支付的功能其实都给结合起来了。“所以这个框架是很有意思的。”朱民直言,“我们对Libra的出世是不应该掉以轻心的,这个对现有的金融体系、货币体系甚至未来的储备体系都会是有很大冲击。”但他也表示,Libra现在有很多问题,比如它的杠杆性问题、储备问题、中央集中的管理体制和机制,都有很多很多问题,它还在非常初始的阶段,能不能成功不知道。[2019/7/1]
1.BloombergGPT优势:特定领域模型仍有其不可替代性且彭博数据来源可靠
《区块链的金融应用》作者Peter:区块链可以帮助发展中国家绕过互联网阶段:《区块链的金融应用》(Blockchain Applications in Finance)一书的作者Peter近日受访Bitcoinist时表示:发展中国家想要加密货币和加密货币的交易。他们的最终目标是完全绕过互联网阶段,直接进入区块链阶段。他举例说,比如在俄罗斯,有俄罗斯版谷歌、Facebook、Uber,但是由于担心被,没人愿意输入信用卡信息。区块链可以改变这一状况,也就是“绕过互联网阶段”。[2018/3/16]
在论文中,彭博社指出,现阶段,通用的自然语言处理模型可以涵盖许多领域,但针对特定领域模型仍有其不可替代性,因彭博社的大多数应用均为金融领域,着手构建了一个针对金融领域的模型尤其优势,同时可以在通用LLM基准测试上保持竞争力:
除了构建金融领域的LLM外,本文的经验也为其他研究领域的专用模型提供了参考。我们的方法是在特定领域和一般数据源上训练LLM,以开发在特定领域和通用基准上表现优异的模型。
中财数字金融交易网 真实性有待商榷 :今日人民网四川频道发布文章称,国内首个加密级数字资产交易平台“中财数字金融交易网”在成都正式上线,该网是一家专注服务于区块链产业的数字资产咨询和交易服务平台。然而,经金色财经调查,在网络上并没有办法找到所谓“中财数字金融交易网”。甚至在某些其他网站的文章中,文章内容相似,但网站名却是“中财数字资产交易网”。据悉,许多国内门户网站的地方站都是外包运营。因此,所谓“中财数字金融交易网”的消息真实性有待商榷。金色财经提醒投资者注意甄别信息来源,多做功课,注意风险,并谨慎投资。[2018/1/4]
此外,我们的训练数据不同于传统的网络爬取数据,网络上的数据总有重复和错误,但我们的数据来源可靠。

2.BloombergGPT的训练数据集:
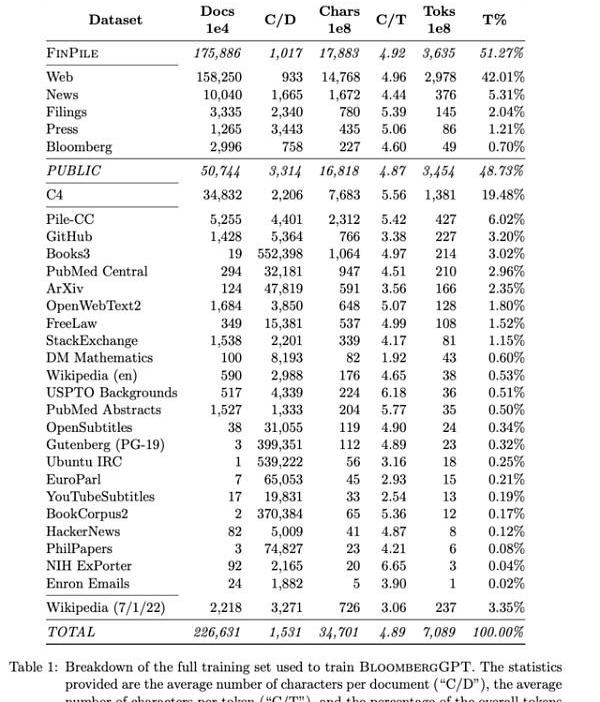
BloombergGPT的训练数据库名为FINPILE,由一系列英文金融信息组成,包括新闻、文件、新闻稿、网络爬取的金融文件以及提取到的社交媒体消息。
为了提高数据质量,FINPILE数据集也使用了公共数据集,例如ThePile、C4和Wikipedia。FINPILE的训练数据集中大约一半是特定领域的文本,一半是通用文本。为了提高数据质量,每个数据集都进行了去重处理。
对金融领域的理解更准
报告指出,在金融领域中的自然语言处理在通用模型中也很常见,但是,针对金融领域,这些任务执行时将面临挑战:
以情感分析为例,一个题为“某公司将裁员1万人”,在一般意义上表达了负面情感,但在金融情感方面,它有时可能被认为是积极的,因为它可能导致公司的股价或投资者信心增加。
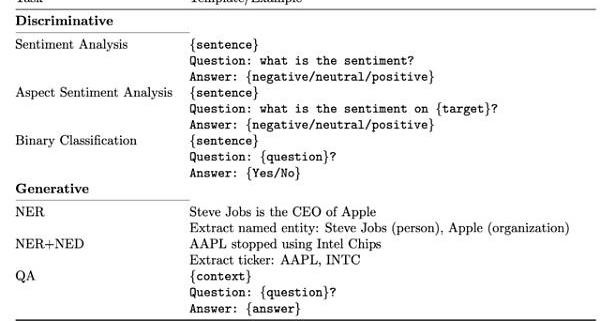
报告指出,从测试来看,BloombergGPT在五项任务中的四项表现最佳,在NER中排名第二。因此,BloombergGPT有其优势性。
测试一:ConvFinQA数据集是一个针对金融领域的问答数据集,包括从新闻文章中提取出的问题和答案,旨在测试模型对金融领域相关问题的理解和推理能力。
测试二:FiQASA,第二个情感分析任务,测试英语金融新闻和社交媒体标题中的情感走向。
测试三:标题,数据集包括关于黄金商品领域的英文新闻标题,标注了不同的子集。任务是判断新闻标题是否包含特定信息,例如价格上涨或价格下跌等。
测试四:FPB,金融短语库数据集包括来自金融新闻的句子情绪分类任务。
测试五:NER,命名实体识别任务,针对从提交给SEC的金融协议中收集金融数据,进行信用风险评估。
对于ConvFinQA来说,这个差距尤为显著,因为它需要使用对话式输入来对表格进行推理并生成答案,具有一定挑战性。
ChatGPT为彭博点赞
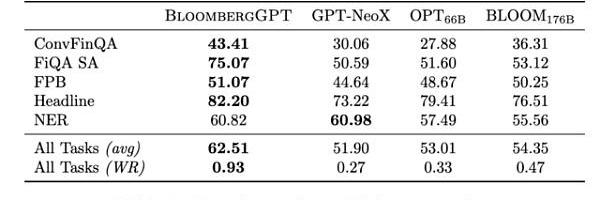
华尔街见闻就这个问题专门询问了ChatGPT,ChatGPT认为BloombergGPT是一项很有意义的技术进步:
它是专门为金融领域开发的一种语言模型,可以更好地处理金融领域的数据和任务,并且在金融领域的基准测试中表现出色。
这将有助于金融从业者更好地理解和应用自然语言处理技术,促进金融科技的发展。同时,BloombergGPT还可以为其他领域的语言模型的发展提供参考和借鉴。总的来说,BloombergGPT是一个有益的技术创新。
DeFi数据1、DeFi代币总市值:520.56亿美元 DeFi总市值及前十代币数据来源:coingecko2、过去24小时去中心化交易所的交易量26.
1900/1/1 0:00:00据《华尔街日报》报道,作为7000人裁员计划的一部分,迪士尼公司已经解散旗下的元宇宙部门。首席执行官RobertIger周一表示,迪士尼的裁员将于本周开始以控制成本并发展“精简”业务,而元宇宙部.
1900/1/1 0:00:00BTC突如其来的上涨打乱了许多投资者的阵脚,在懊悔踏空之余,大家又开始思考:比特币今年还会上涨吗?撰文:Jack2022年底市场进入深熊以来.
1900/1/1 0:00:00受Arbitrum「撒钱」刺激,业界的空投热情再次被点燃,而ZKRollup系Layer2们则成为了所有羊毛党们关注的焦点.
1900/1/1 0:00:00目前SUINetwork没有正式的空投计划,但是SUINetwork已经发布了SUIToken社区访问计划,以及SUIToken的分配细节。Sui是一种基于Move语言的主要新L1公链之一.
1900/1/1 0:00:007:00-12:00关键词:SushiSwap、peedan.eth、林俊杰、a16z1.安全团队:SushiSwap项目疑似被攻击.
1900/1/1 0:00:00