LanguageModel
长期一来,人类一直梦想着让机器替代人来完成各种工作,其中也包括语言相关工作,如翻译文字,识别语言,检索、生成文字等。为了完成这些目标,就需要机器理解语言。最早人们想到的办法是让机器模拟人类进行学习,如学习人类通过学习语法规则、词性、构词法、分析语句等学习语言。尤其是在乔姆斯基提出“形式语言”以后,人们更坚定了利用语法规则的办法进行文字处理的信念。遗憾的是,几十年过去了,在计算机处理语言领域,基于这个语法规则的方法几乎毫无突破。
统计语言模型
另一个对自然语言感兴趣的就是香农,他在很早就提出了用数学的方法来处理自然语言的想法。但是当时即使使用计算机技术,也无法进行大量的信息处理。不过随着计算机技术的发展,这个思路成了一种可能。
首先成功利用数学方法解决自然语言问题的是贾里尼克(FredJelinek)及他领导的IBMWason实验室。贾里尼克提出的方法也十分简单:判断一个词序列是否合理,就看他的可能性有多大。举个例子:判断“Ihaveapen”翻译为中文”我有个笔“是否合理,只需要判断”Ihaveapen.我有个笔”这个序列的可能性有多大。而如何判断一个词序列的可能性,就需要对这个词序列的概率进行建模,也就是统计语言模型:S表示一连串特定顺序排列的词w1,w2,…,wn,n是序列的长度,则S出现的概率P(S)=P(w1,w2,…wn).
但是这个概率P(S)很难估算,所以这里我们转化一下。首先,利用条件概率公式将其展开:
P(S)=P(w1,w2,..wn)=P(w1)?P(w2|w1)?P(w3|w1,w2)?…?P(wn|w1,w2,..wn?1)
即:
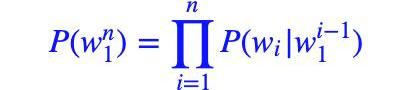
?接着,我们利用马尔可夫假设,即任意一个词wi出现的概率只与其前一个词wi?1)有关。于是,问题就变的简单了许多。对应的S的概率就变为:
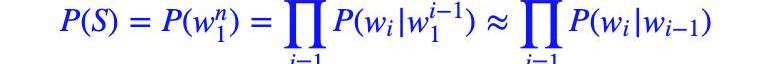
以上对应的便是一个二元模型,当然,如果词由其前面的N?1个词决定,则对应的是N元模型。
神经网络语言模型
统计语言模型有很多问题:1.训练语料中未出现过的词如何处理(OOV);2.长尾低频词如何平滑;3.one-hot向量带来的维度灾难;4.未考虑词之间的相似性等。
为了解决上述问题,YoshuaBengio(深度学习三巨头之一)在2003年提出用神经网络来建模语言模型,同时学习词的低纬度的分布式表征(distributedrepresentation),具体的:
1.不直接对P(wn1)建模,而是对P(wi|wi?11)进行建模;
2.简化求解时,不限制只能是左边的词,也可以含右边的词,即可以是一个上下文窗口(context)内的所有词;
3.共享网络参数。
具体形式如下:
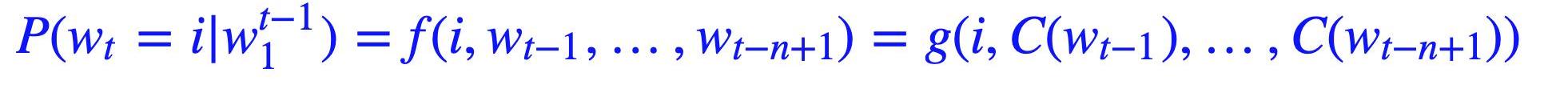
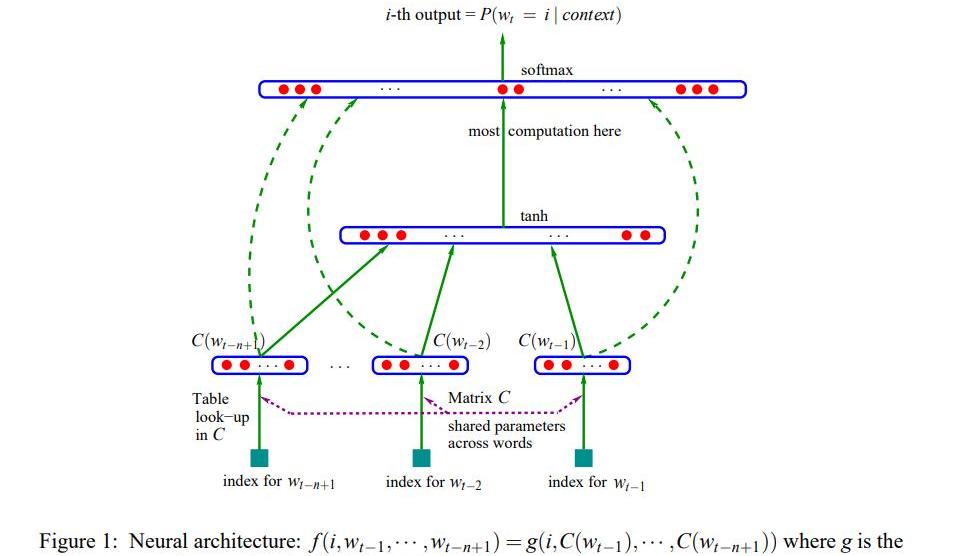
由于当时的计算机技术的限制,神经网络语言模型的概率结果往往都不好,所以当时主要还是用这个形式训练词向量。
升级
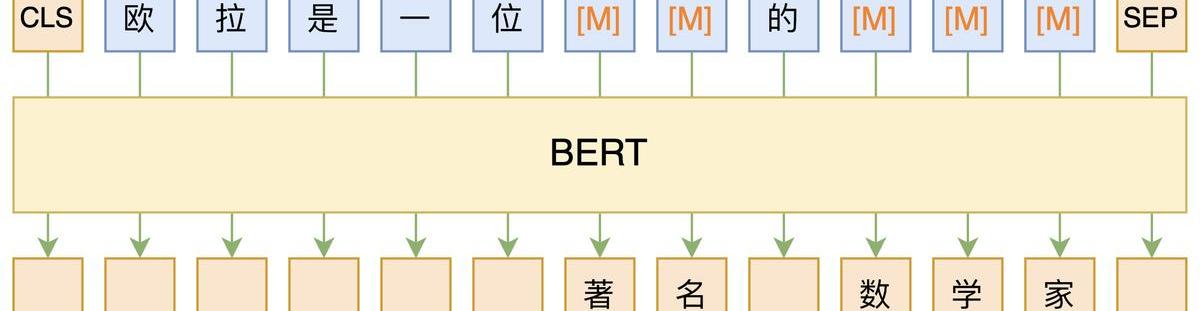
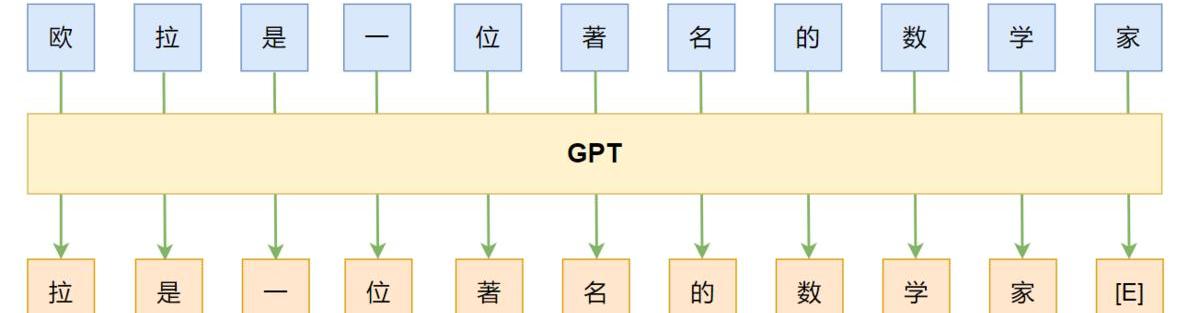
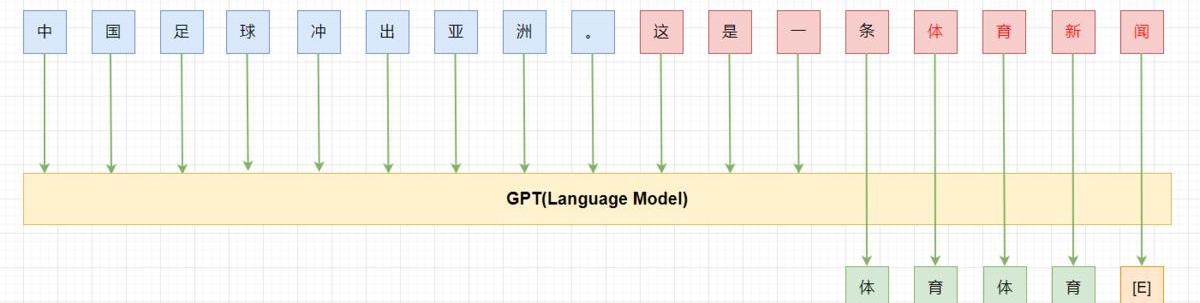
随着数据、算力、模型架构、范式等的升级,神经网络语言模型也得到了长足的发展。如模型架构从mlp到cnn/rnn又到目前的transformer-base,对应的能力也在不断发展,从之前只对P(wi|wi?1)建模,通过”“并行”或“串行”的方式,也可以对P(wni)建模。求解NLPtask从原来的word2vector+ML发展为pretrain+fine-tuning。目前最有代表性的就是BERT和GPT。
98,440,822枚USDC在USDC Treasury销毁:金色财经报道,WhaleAlert数据显示,北京时间今日1:52,98,440,822枚USDC(98,440,822美元)在USDC Treasury销毁。[2023/4/18 14:09:28]
BERT:双向,autoencoding,MLM,encoder
GPT:left-to-right,autoregressive,LM,decoder
GPT-3
随着NLP进入BERT时代后,pretrain+finetune这种方式可以解决大量的NLP任务,但是他依然有很多限制:
1.每个任务都需要大量的标注数据,这大大限制了模型的应用。此外,还有大量不好收集标注数据的任务存在;
2.虽然pretrain阶段模型吸收了大量知识,但是fine-tuned后模型又被“缩”到一个很窄的任务相关的分布上,这也导致了一些问题,比如在OOD(out-of-distribution)上表现不好;
3.如果参考人类的话,人类通常不需要在大量的标注数据上学习后才能做任务,而只需要你明确告知你想让他干嘛或者给他几个例子(比如:蓝色->blue,绿色->green,红色->),之后便能处理新的任务了。
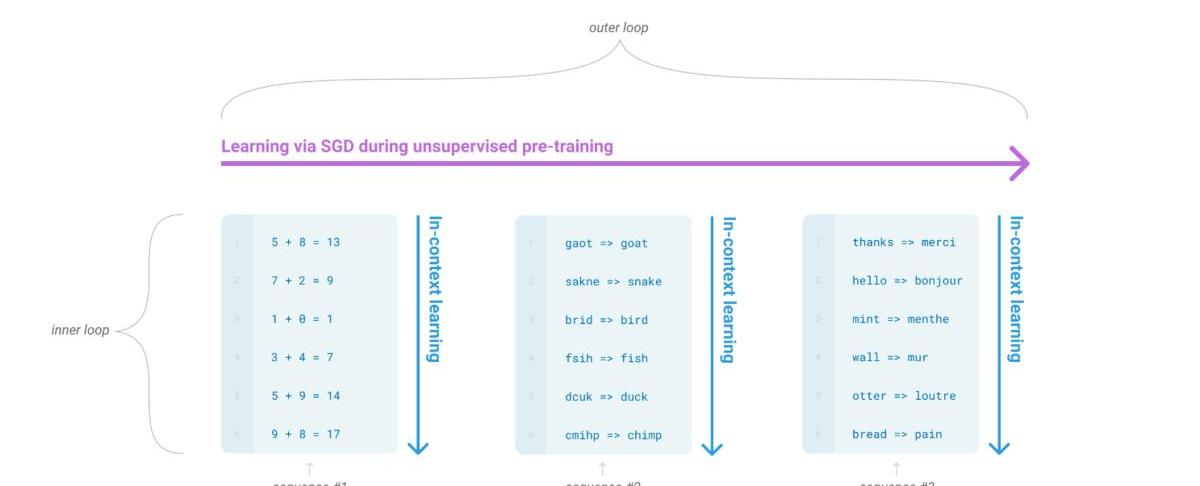
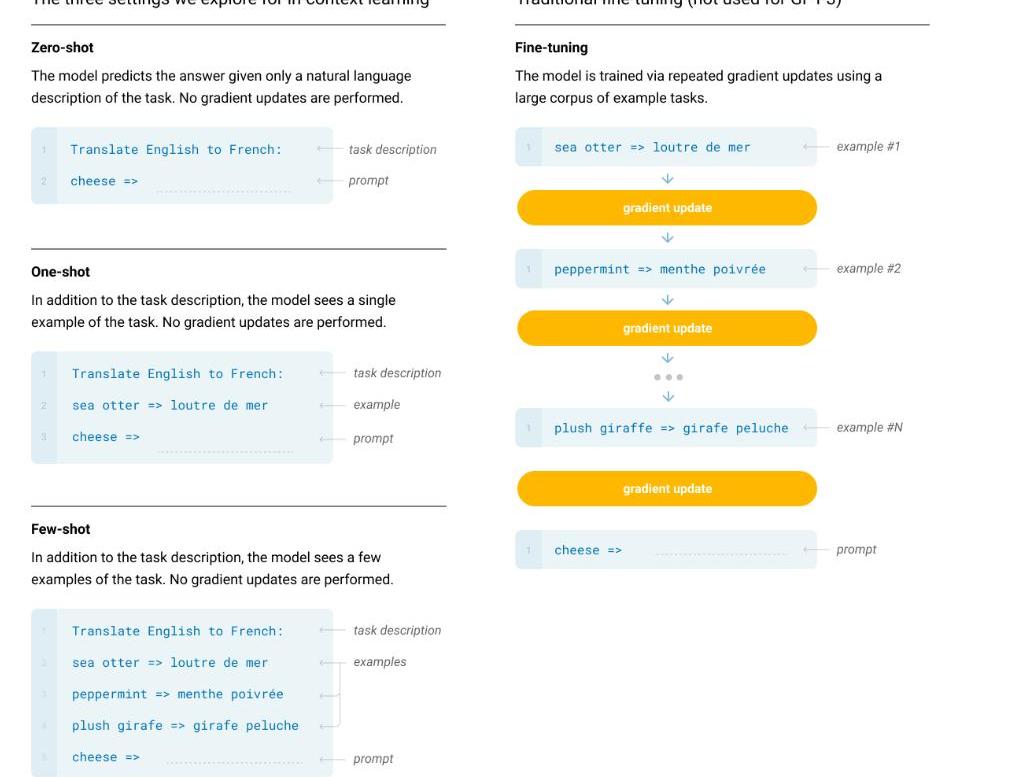
而我们的一个终极目标就是希望模型能像人这样,灵活的学习如何帮助我们完成工作。一个可能的方向就是元学习(meta-learning):学习如何学习。而在LM语境下,即我们希望LM在训练的时候能获得大量的技能和模式识别的能力,而在预测的时候能快速将技能迁移到新任务或者识别出新任务的要求。为了解决这个问题,一个显现出一定有效性的方法就是”in-contextlearning”:用指令(instruction)或者少量示例(demonstrations)组成预训练语言模型的输入,期望模型生成的内容可以完成对应的任务。根据提供多少个示例,又可以分为zero-shot,one-shot,few-shot。
虽然in-contextlearning被证明具有一定的有效性,但是其结果相比fine-tuing还有一定的距离。而随着预训练语言模型(PTM)规模的扩大(scalingup),对应的在下游task上的表现也在逐步上升,所以OpenAI就猜想:PTM的进一步scalingup,对应的in-contextlearning的能力是不是也会进一步提升?于是他们做了GPT-3系列模型,最大的为GPT-3175B。

最终的模型效果简单总结一下:一些任务上few-shot(zero-shot)能赶上甚至超过之前fine-tunedSOTA(如:PIQA),有些任务上还达不到之前的SOTA(如:OpenBookQA);能做一些新task,如3位数算数。
不过他们也发现了模型存在的一些问题,并提出了一些可能的解决方案。

Promptengineering
zero-shot/few-shot这种设定确实给NLP社区带来了新的思路,但是175B的模型实在是太大了,即不好训练又不好微调也不好部署上线,如何在小模型上应用呢?此外,不同的pattern(prompt)下同一个task的效果差距也非常大,如何找到效果最好的prompt呢?于是大家就开始花式探索prompt,NLPer也变成了prompt-engineer(误).PS:prompt的语义目前即可以指模型的输入,也可以指输入的一部分。
Galaxy Digital创始人:现在是购买黄金、白银和比特币的最佳时机:金色财经报道,Galaxy Digital创始人兼首席执行官Michael Novogratz表示,美国正面临信贷紧缩,现在是购买黄金、白银和比特币的最佳时机。他在接受CNBC采访时解释说:“美国和全球都将面临信贷紧缩。你应该投资黄金和白银……还有比特币。”
他指出,银行通常通过减少放贷来重建资本,这意味着信贷紧缩即将到来,他指出,大宗商品市场等指标已经预示着经济衰退。除了对美国经济艰难时期的预测外,Novogratz还表达了对加密货币的看涨情绪。(Cointelegraph)[2023/3/16 13:07:54]
PET
PET(Pattern-ExploitingTraining)应该是第一个在小模型上在few-shot设定下成功应用的工作。
PET的主要思路是:
用通顺的语言为task构造一个pattern(prompt),如:“下面是{label}新闻。{x}”;将label映射为文字。如:“0->体育,1->财经,2->科技”;将样本按照pattern进行重构,冻结模型主体,只更新label对应的token(embedding),继续LM(MLM)训练;预测时,将label对应位置的token再映射回label。
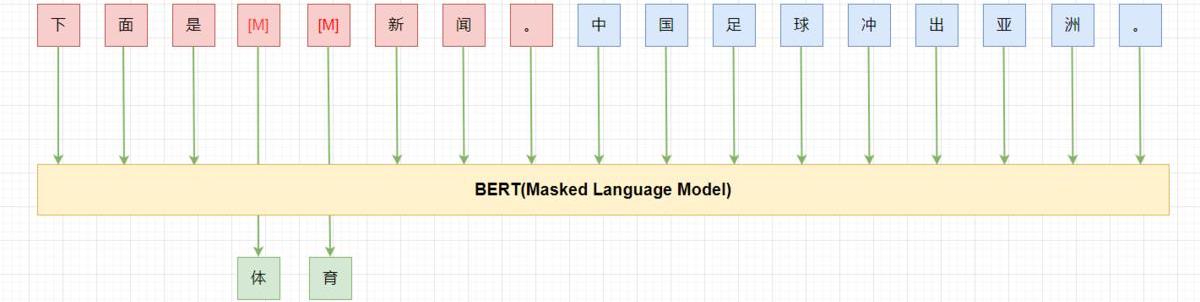
PET在few-shot的设定下,利用BERT-base就能获得比GPT-3175B更好的结果。不过pattern是需要人来构造的,pattern的“好坏”直接影响最终的效果。
思考:PET中的fine-tuning是与其pretrain的形式是一致的,而pretrain与fine-tuning形式一致能够work才是一种“自然”的事情,pretrain+fine-tuning这种下游任务与预训练形式不一致能work其实不是一个自然的事情,为什么pretrain+fine-tuning能work值得思考。
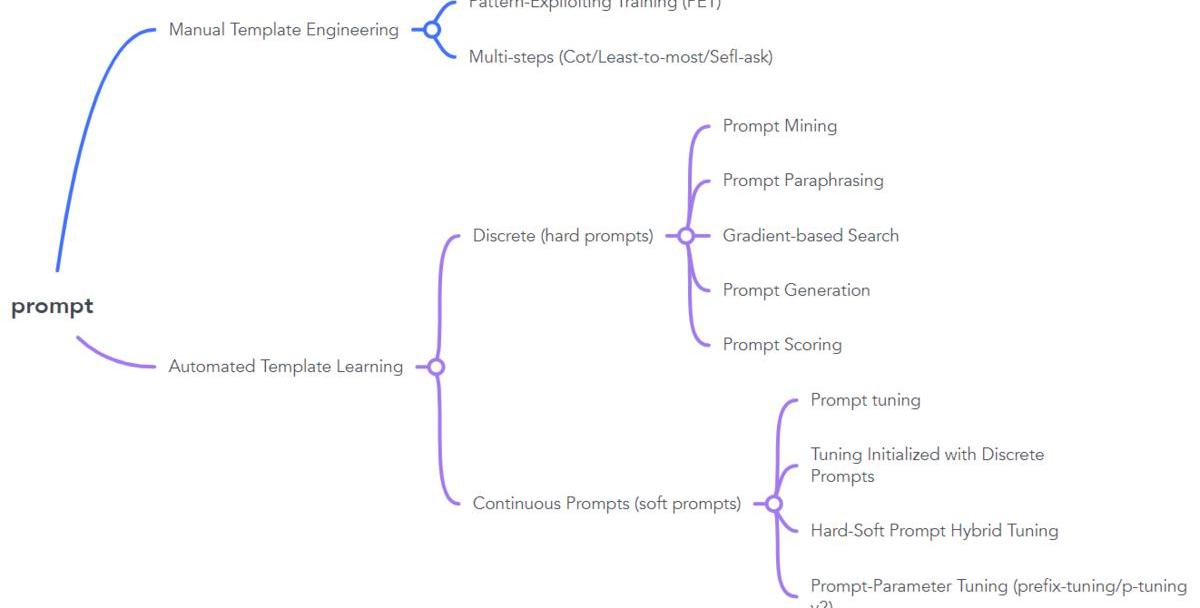
AutomatedDiscretePrompt
人来写prompt还是需要大量的时间和经验,而且,即使一个经验丰富的人,写出的prompt也可能是次优的。为了解决这些问题,一种办法就是“自动”的帮助我们寻找最优的prompt。
PromptMining:该方法是在语料上统计输入X与输出Y之间的中间词或者依赖路径,选取最频繁的作为prompt,即:{X}{middlewords}{Y}.PromptParaphrasing:该方法是基于语义的,首先构造种子prompts,然后将其转述成语义相近的表达作为候选prompts,通过在任务上进行验证,最终选择效果最优的。Gradient-basedSearch:通过梯度下降搜索的方式来寻找、组合词构成最优prompt。PromptGeneration:用NLG的方式,直接生成模型的prompts。PromptScoring:构造模型对不同的prompt进行打分,选择分数最高的prompt作为最优prompt。AutomatedContinuousPrompt
虽然PET最初在构造prompt时认为prompt需要是通顺流畅的自然语言。而随着各种自动化方法构造出了很多虽然句子不通顺但是效果更好的prompt,大家也发现:通顺流畅的自然语言或者是自然语言的要求只是为了更好的实现预训练与下游任务的“一致性”,但是这并不是必须的,我们其实并不关心这个pattern具体长什么样,我们真正关心的是他有哪些token组成,都插入在什么位置,输出空间是什么,以及最重要的在下游任务上表现有多好。
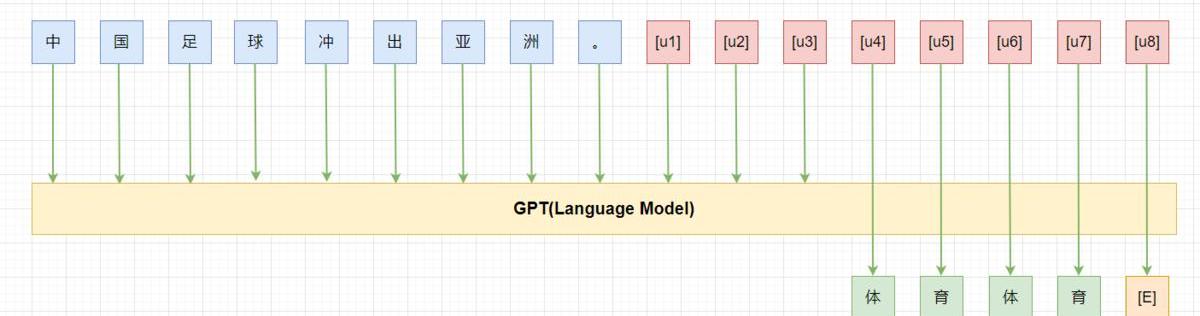
如上图所示,其中为unusedtoken,我们在tuning时依然冻结模型的参数,只微调这8个token。
prompttuning:利用N个unusedtoken/newtoken构造prompt,然后微调这N个token。其中N是个超参数。TuninginitializedwithDiscreteprompts:用手工构造的prompt或者自动搜索的离散prompt初始化需要微调的token,然后进行prompttuning,有利于提高准去率。Hard-SoftPromptHybridTuning:这类方法将手动设计和自动学习相结合,增强prompttoken之间的相关性。如p-tuning首先通过一个LSTM训练手工设计的prompt中插入的可学习的token来增强prompt之间的相关性,让prompttoken更接近“自然语言”。Prompt-parameterTuning:仅仅训练prompttoken效果不够好,将其与fine-tuning结合。如prefix-tuning,在输入前增加可学习的prompttoken的同时,在模型每层都增加一部分可学习参数。Multi-StepReasong(三步走)
Vertex Protocol公布其代币经济学,将通过分配VRTX实现社区治理:1月28日消息,去中心化外汇平台Vertex Protocol公布其代币经济学,将通过分配VRTX实现社区治理,并提供额外的实用程序。VRTX主要功能是实现用户去中心化参与Vertex,并创建流动性质押代币xVRTX和不可转让代币voVRTX。在主网上,用户可以通过至少两周的解锁期来抵押VRTX,以获得流动性可转让的代币xVRTX。
Vertex Protocol此前于2022年4月完成850万美元种子轮融资。[2023/1/28 11:34:06]
虽然大模型在很多task都证明了其有效性,但是这些task都是System1thinking,而System2thinking任务需要更多的数学、逻辑以及常识推理。大模型对这类任务还做不好目前,如数学推理、符号推理等。Ourresponsestothesetwoscenariosdemonstratethedifferencesbetweenourslowerthinkingprocessandourinstantaneousone.System1thinkingisanear-instantaneousprocess;ithappensautomatically,intuitively,andwithlittleeffort.It’sdrivenbyinstinctandourexperiences.System2thinkingisslowerandrequiresmoreeffort.Itisconsciousandlogical.–?system-1-and-system-2-think
如GPT-3175B在GSM8K上直接fine-tuning也只能得到33%的准确率,通过在fine-tunedmodel上进行采样,再标注答案是否正确,然后训练一个verifier来判断生成的答案是否正确,最终也只能得到55%,而一个9-12岁的孩子平均能得到60%。所以,OpenAI的研究员认为,如果想达到80%以上,可能需要把模型扩大到10??16
。
然而,后续的工作Gopher却给这个思路泼了盆冷水:即使继续放大模型,模型在这种推理任务上的表现也不会显著提升。也许语言模型就不能做推理这种system2thinkingtask。
CoT
“不就是个张麻子嘛,办他!”(误)不就是推理嘛,LLM也能做,只需要向人学习一下就行了。
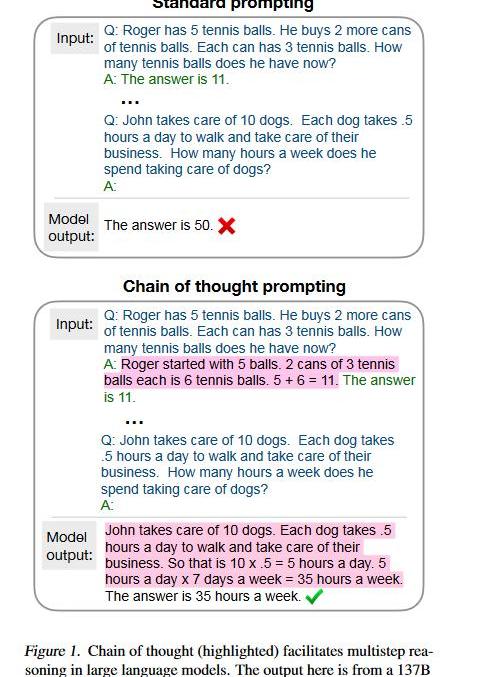
回想读书时做数学应用题目,老师总是要求你写清解题步骤。而之前的方法总是让模型一步到位,直接给出答案,所以模型考不好。现在我们让模型像人类推理一样,先给出思考步骤(chainofthought),然后再给出答案,模型的推理能力就能大大提高了。而这个思路,只需要few-shot(8examples)就能达到58.1%的准确率,超过之前GPT-3175Bfine-tuning+verifier。除了GSM8K这种算术推理外,在符号推理、尝试推理任务上CoT也是能将模型的性能提升一大截。
CoT确实很酷,改变了我们之前对LLM的认知,但是还不够酷:很多时候我们不一定能凑够8个样本(我就无法快速给出8个带有解题步骤的数学题),那能不能在zero-shot下让模型自己给出解题思路跟答案呢?
“Let’sthinkstepbystep.”
没错,答案就是这句话。只要在输入后面加一句”Let’sthinkstepbystep.”哄哄模型,模型就会自己按照CoT的方式先生成解题思路,然后再生成对应的答案。PS:这句话是试出来的,还有很多类似的表达但是效果不如这句好。

9-12yearolds(Cobbeetal,.2021)60FinetunedGPT-3175B33FinetunedGPT-3+verifier55PaLM540B:standardprompting17.9PaLM540:chainofthoughtprompting58.1GPT-3175B+Complexity-basedConsistency72.6PaLM540B:Cot+majorityvoting74.4Codex175B(GPT3.5)+complexchainsofthought82.9PaLM540B:Zero-Shot12.5PaLM540B:Zero-Shot-Cot43PaLM540B:Zero-Shot-Cot+selfconsistency70.1
资管公司Simplify向美SEC提交ETF申请,拟将总资产的15%投资GBTC:10月28日消息,资产管理公司Simplify向美国证券交易委员会(SEC)提交交易所交易基金(ETF)申请,该ETF名为The Simplify U.S. Equity PLUS GBTC ETF(SPBC),将至少80%的净资产投资于美国公司的股票和灰度比特币信托(GBTC),其中预计将总资产的15%投资于GBTC,以间接获得加密货币敞口,该基金不会直接投资于比特币、比特币期货或其他加密货币。[2022/10/28 11:53:38]
Zero-Shot-Cot就能获得43%的准确率,而Zero-Shot-Cot+selfconsistency甚至可以获得70.1的准确率。
Zero-Shot-CoT+selfconsistency:按照Zero-Shot-Cot的方式,通过采样(sample)让模型生成多个结果,然后对答案进行投票。
目前在GSM8K上的SOTA是82.9,看来不需要继续放大模型,只需要正确使用模型。
关于CoT来源的问题,目前的主要推论是可能来自预训练时数据中包含了代码数据(code),主要论据为:1.GPT-3.5(Codex)有CoT能力,PaLM也有,而其他LLM却没有,这两个模型与其他模型的一个主要区别就是增加了代码数据;2.有工作认为CoT与代码的自然语言翻译形式相同,所以CoT可能来自这种能力的迁移。
Least-to-MostPrompting
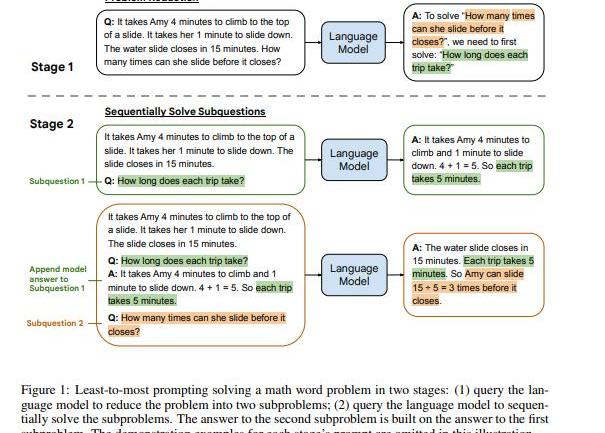
如果仔细对比CoT和之前的prompt的话,其中最大的不同是CoT模仿人类推理将过程分为多个阶段。而有些问题如组合泛化直接用CoT也不好解决。于是就提出了另一种多步推理的方法,Least-to-MostPrompting:
首先将问题分解为子问题“Tosolve{Q},weneedtofirstsolve:sub-q”,得到子问题的答案后再来给出最后的答案.
self-ask
self-ask:先让LLM自问自答生成多跳问题与答案,然后再生成最终的答案。

扩展测试
以上的实验都是基于事实的推理,但是我想看看模型是不是有类似反事实推理的能力,所以我做了三个测试:
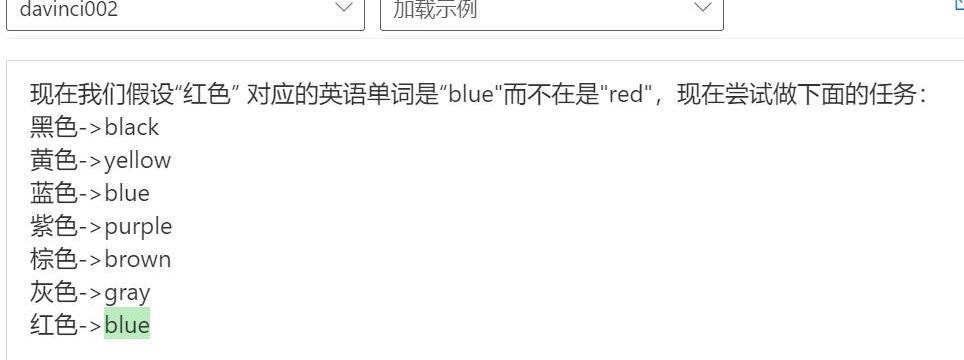
第一次我直接让他解释一个反事实的东西;第二次设定一个反事实(红色对应单词是”blue”),基于此让他做一个翻译任务;第三次,在给出的例子里增加相应的事实(蓝色->blue),继续让他做这个翻译任务。

实验1

实验2
实验3
三个测试结果显示模型确实有很强的推理能力,包括反事实的推理能力。此外,实验二、三显示模型有很强的基于prompt推理的能力,甚至要想更正prompt里错误的信息需要花点心思才行。
PS:后面两次测试只是证明了模型”能“基于prompt做推理,而无法证明模型”总是“基于prompt做推理。
思考:
目前流行的RAG(Retrieval-AugmentedGeneration)是不是基于模型具有的这种推理能力?LLM表现出的能胡说八道(Hallucinations)是否也是由模型具有这种反事实推理带来的?以及如何让”胡说八道“变成”创造“。这种能力也带来了一个问题:模型生成的答案并不是预训练数据优先(pretraindatafirst),如果我们的prompt里出现了反事实的东西(retrieval/dialogquery/demonstration),那模型就很可能生成一个”错误“的答案。EmergentAbilities
goblintown.wtf系列NFT24小时交易额为102.41万美元:金色财经消息,据NFTGo.io数据显示,goblintown.wtf系列NFT总市值达6238万美元,在所有NFT项目总市值排名中位列第39;其24小时交易额为102.41万美元,跌幅达9.35%。截止发稿时,该系列NFT当前地板价为3.15ETH,跌幅为26.01%。[2022/6/12 4:19:11]
既然LLM有这么多神奇的能力,包括Zero-Shot-CoT这种推理能力。那我们之前这么多人用手工的或者自动的方式构造prompt,为什么没找到”Let’sthinkstepbystep”这句话呢?
原因可能是你的模型不够大。随着LLM不断的放大,当他大到一定规模时,他会突然显现出新的能力,即”涌现能”力(EmergentAbilities)。而即使是今天,我们大部分人接触的模型还是1B以下的,LLM中被称作”smallmodel”的T5-11B大部分人也用不起来,这就限制了我们发现LLM的各种能力。
Emergency的原始含义是指量变引起质变,即:
Emergenceiswhenquantitativechangesinasystemresultinqualitativechangesinbehavior.
而在LLM语境下,其含义为在小模型中没有而在大模型中出现的能力,即:
Anabilityisemergentifitisnotpresentinsmallermodelsbutispresentinlargermodels.ScalingUp
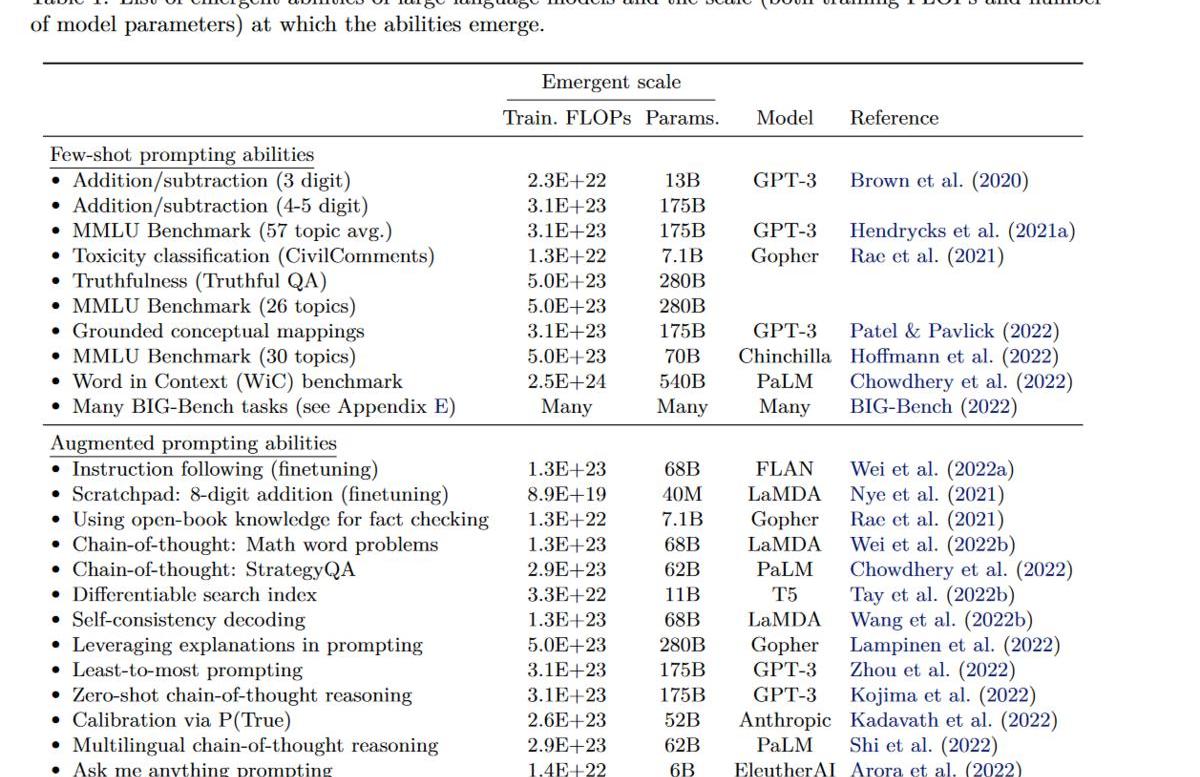
上表是目前已有工作中涌现各种能力的模型及其最小规模。基本可以认为你需要至少68Bparametermodel(前提训练的OK)才能涌现新能力。而这里涌现新能力指的是性能优于随机,而要达到可用,你可能需要继续放大模型。如CoT至少需要GPT-3175B才能优于精调小模型(t5-11b).
此外,与模型性能有关的不光有参数量,还有数据大小,数据质量,训练计算量,模型架构等.合理的比较应该是性能最好的LLM在参数量上进行比较,然而我们目前还不知道如何训练让LLM达到最优,所以同一个能力在不同模型上需要的参数量也不相同,如要涌现出2位数乘法的能力,只需要GPT-313B,而在LaMDA却需要68B。
所以除了规模外,还有别的因素影响着是否能出现新能力:
模型如何训练的,很多模型即使参数足够大,有些能力也可能不会出现。如原始GPT-3175B、bloom-176B等虽然参数够大,但是却都没有CoT的能力。LLM的使用方法,fine-tuning/标准的prompt方法在推理任务上效果不好,即使在GPT-3175B上效果也达不到中学生平均水平,而CoT却只要100Bparametermodel即可超越之前最好结果。如何提升模型能力,在followinstruction上,之前的工作认为至少需要68Bparametermodel才能有效instruction-finetuning,而后续的flan-t5却在11B上就得到了更好的性能;GPT-3经过RLFH后的InstructGPT,在followinstruction上,1.3B就已经比之前的GPT-3175B性能更好。模型的架构,上面的结果都是transformer-based的,而有工作验证了其他模型架构(RNN/MLP),最后结论是其他架构即使放大,也无法像transformer-basedmodel一样涌现能力。again:attentionisallyouneed!Alignment
到目前为止,我们已经知道了LLM有很多能力,而且随着模型规模的扩大,可能会出现更多的新能力。但是,有个问题却严重制约着他在实际中的应用:promptengineering。仔细思考一下这个问题,其本质其实是模型认为处理一个task的prompt跟我们以为的不一样,如我们认为当我们说“问答:”时模型就应该知道后面的是一个QAtask,而模型可能觉得,如果你想让我做QAtask,你需要告诉我”妈咪妈咪哄”。
这就好比至尊宝已经得到了月光宝盒,但是却需要找到“般若波罗蜜”这句口诀然后喊出来才能穿越一样,而且环境稍微不同,具体穿越到哪还不一定。那更好的方式应该是我们拿到月光宝盒,然后说一句:我要穿越到白晶晶自杀前五分钟,然后我们就穿越到了对应的时空。
理想情况下,LLM应该正确理解用户的指令,包括同一个任务的不同描述。而LLM训练时的任务是预测下一个时刻的词(predictnexttoken),而非处理用户的指令(followinstruction),所以存在gap也是很自然的事。为了缓解这个问题,一个方法就是进行“对齐”(Alignment),缩小模型与人类对同一个instruction之间理解的gap,从而让模型能更好的理解用户的指令。
Fine-tuningwithhumanfeedback
一种很直接的想法就是构造数据进行fine-tuning。所以为了让模型更好的理解人类的指令,我们需要通过人类反馈进行微调模型。
SFT
构造人类真实场景中的指令即期望的输出,然后直接进行SFT。
FeedME
进过SFT后模型可能已经能很好的理解人类指令了,但是其答案可能有其他问题,如胡编乱造,包含敏感内容等,此外,靠人写数据成本高又耗时,所以我们可以对多个模型的结果进行打分(7分),然后在7/7的数据上继续训练,对多个模型的最好结果进行蒸馏(distill)。这个方法叫FeedME(FeedbackMadeEasy).
Reinforcementlearningwithhumanfeedback
即使我们从人写完整的样本转换为人给模型采样的结果进行打分,整个流程依然需要人参与,也限制了整个流程的加速。为了更高效的进行整个微调的流程,引入Reinforcementlearning。该方法又叫RLHF。
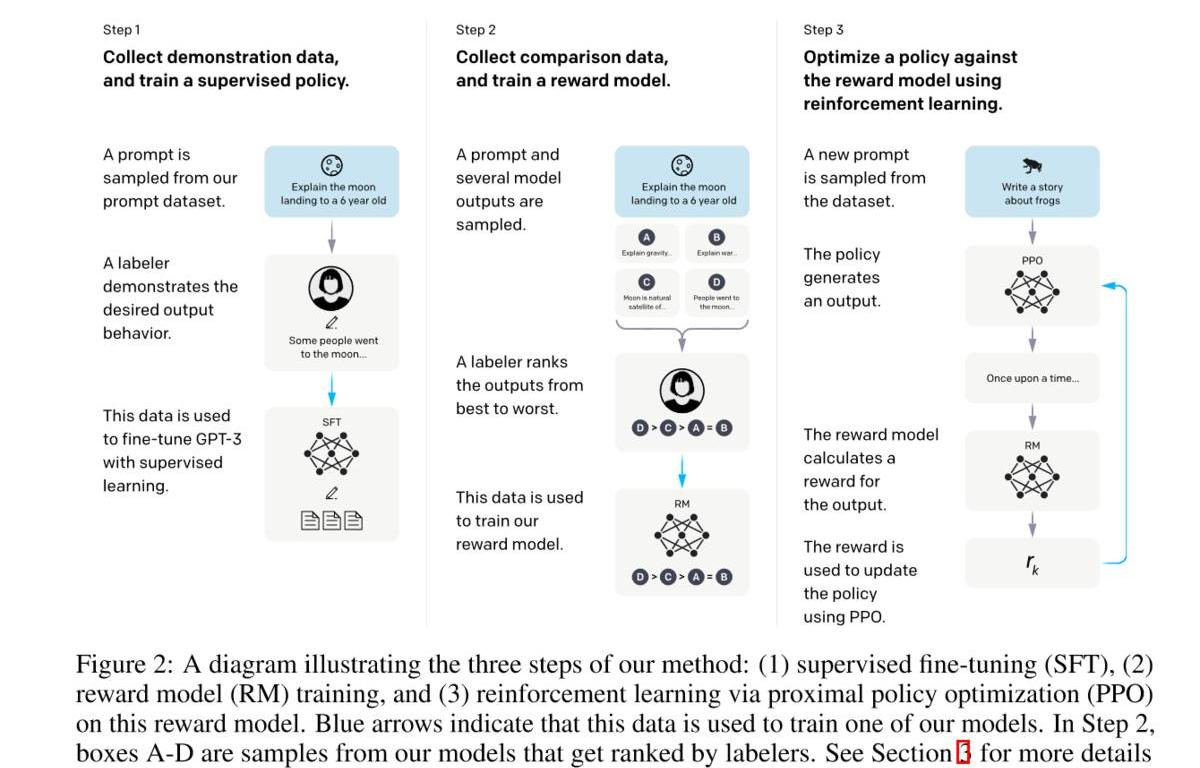
具体流程:
标注人员手写(prompt,completion),然后进行SFT。这里主要是得到一个比较好的初始化模型,即模型至少能有一定的followinstruction的能力。收集模型输出并进行打分,然后训练一个rewardmodel。利用强化学习优化模型。
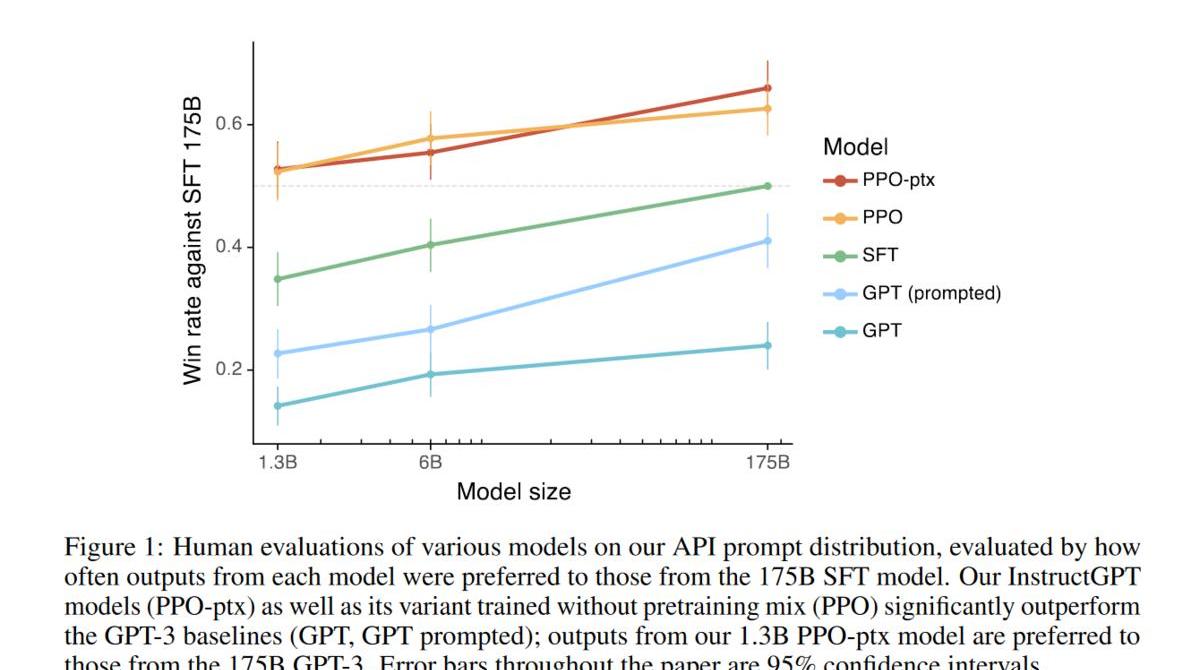
结果上看,效果显著,1.3B就超过了之前175B的结果,而且随着模型增大,结果也在上升。
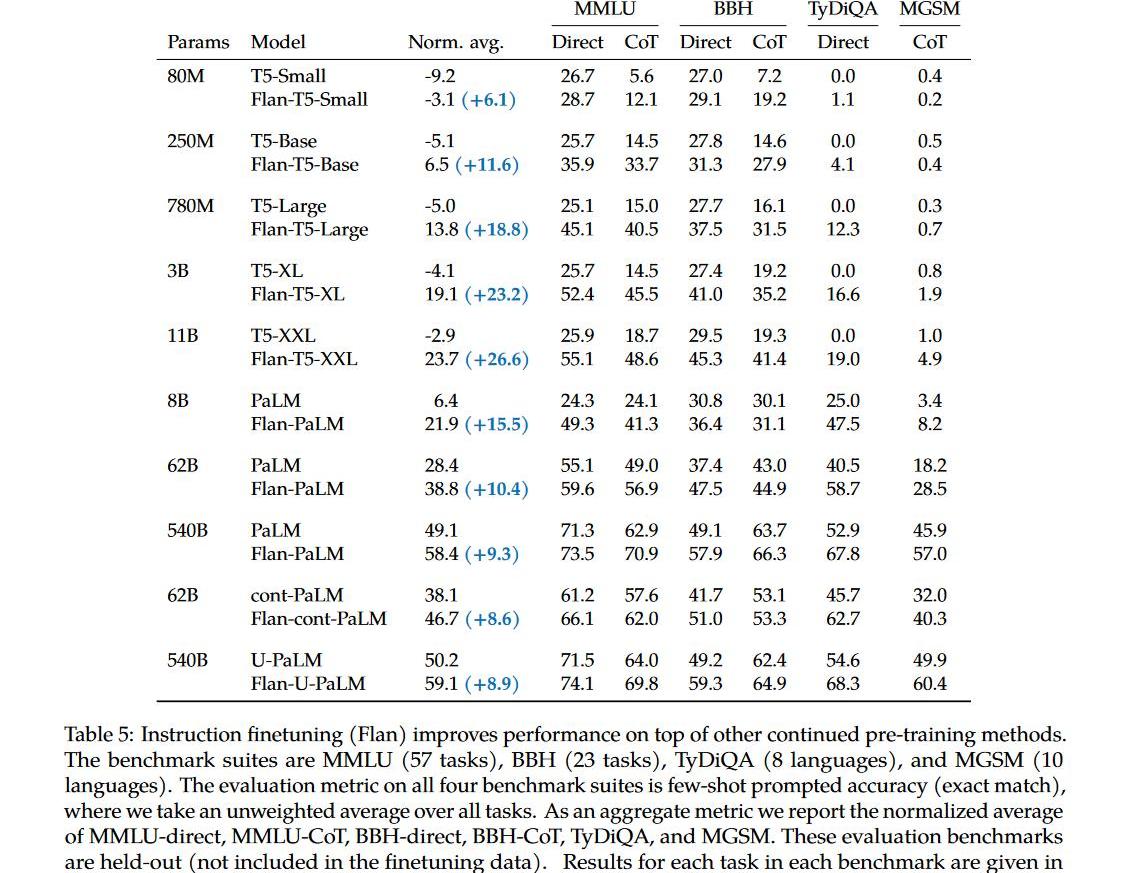
Instruction-tuning
虽然fine-tuningwithhumanfeedback可以提升LLM在真实场景中用户任务上(customertask)的性能,但是在学术任务上的性能却会有所下降,即使OpenAI尝试在RL中增加部分pretraindata同时增加LMloss来尝试缓解这个问题,但是依然没有解决。
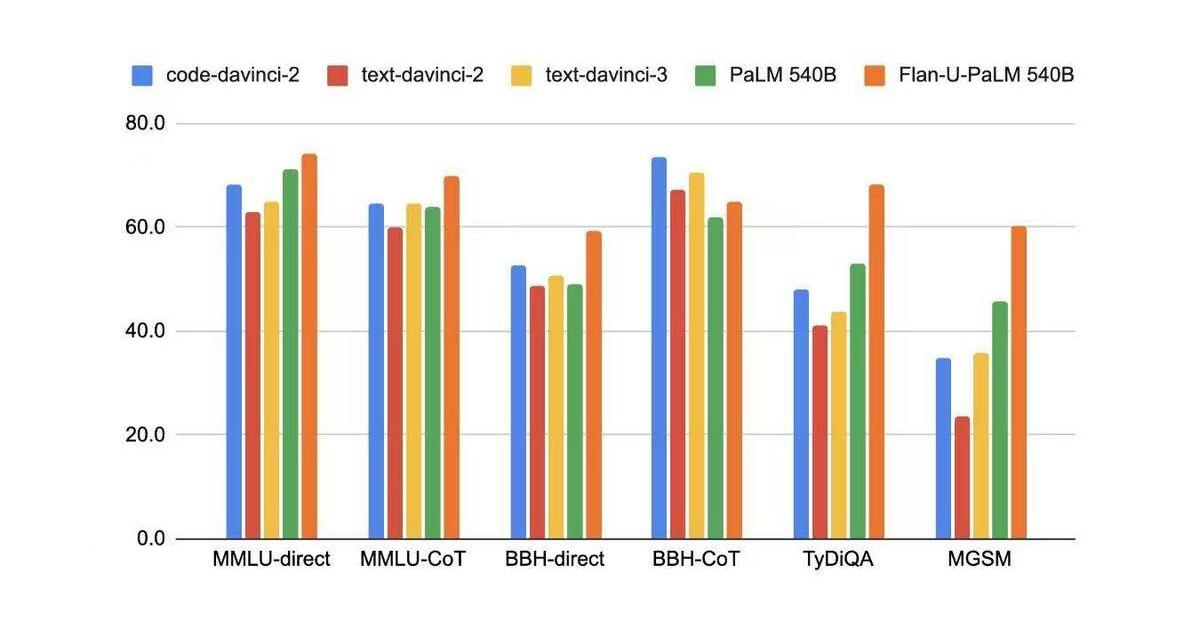
如何解决这个问题呢?办法就是instruction-tuning:
利用academicNLPdata,为其构造对应的zero-shot/few-shot/CoTpattern,然后进行fine-tuning。
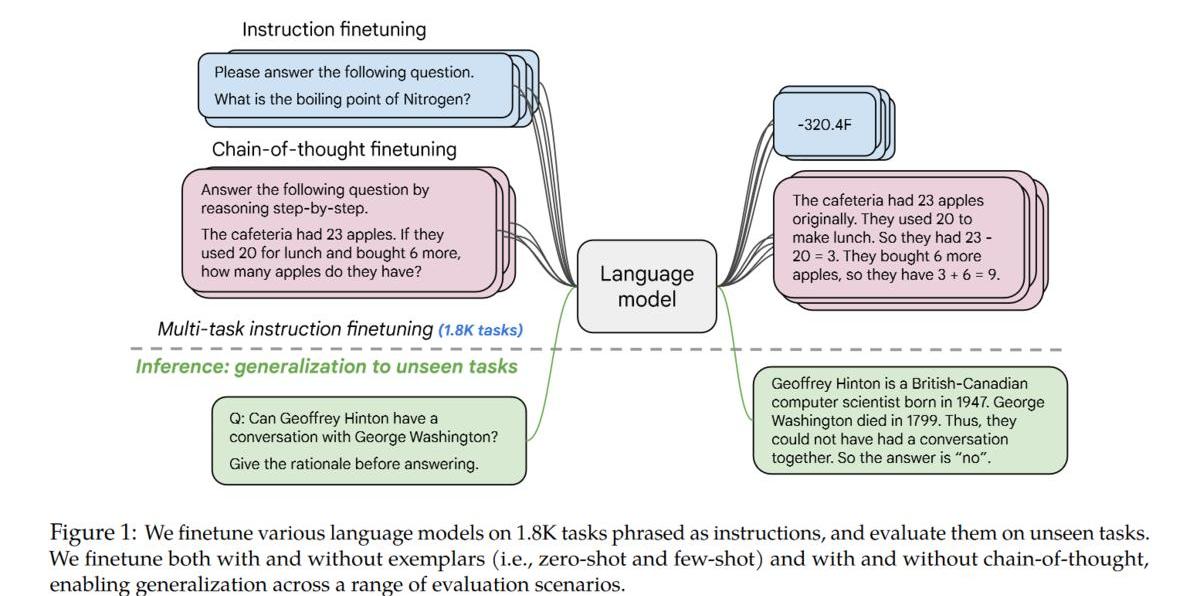
instruction-tuning效果显著:
1.不光能提升大模型在academicNLPbenchmark上的性能,也能提升小模型上的性能;
2.能提升instruction-tuning时未见过的task上的性能;
3.能解锁小模型上的CoT能力;
4.随着任务数量的增加,对应的提升也会增加。
5.最重要的是也能提升LLM理解人类真实指令(followinstruction)的能力。
ps:虽然followhumaninstruction的能力提升了,但是跟InstructGPT谁的性能更好却没有对比,我猜应该是不如InstructGPT,实际应用/学术指标两者依然是天枰的两端。
ChatGPT
那如何才能得到一个ChatGPT呢?
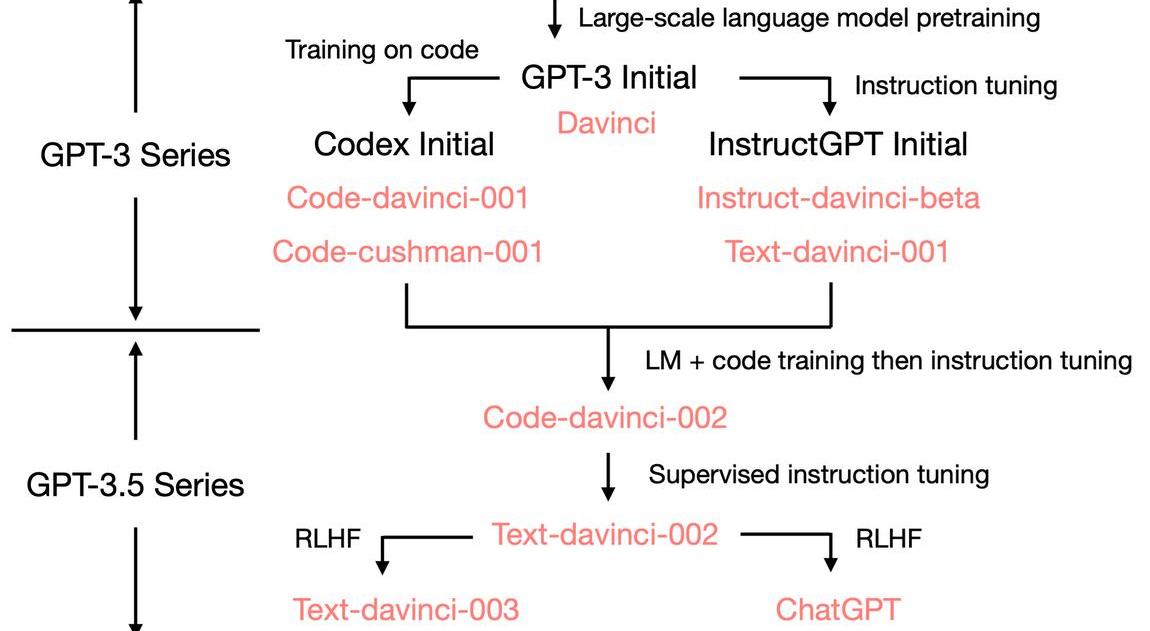
首先我们需要一个具备各种能力(潜力)的LLM,所以它要足够大,训练的足够好。OpenAI大概率也是为此重新训练了一个GPT-3模型,主要论据为:1.原始GPT-3175B和复现GPT-3的OPT-175B都没有CoT能力,而GPT-3.5有CoT;2.原始的GPT-3的窗口只有2048,而其对应的是绝对位置编码,现在的GPT-3.5最大窗口为8192。3.原始的GPT-3不能写代码,现在的可以。标注人员手写符合人类的instructiondata(最好再混合一些academicinstructiondata,如:Flan),然后进行SFT,让模型能更好的followinstruction。在对话场景下构造对应的instructiondata,进一步fine-tuningwithhumanfeedback(RLHF加速流程).
番外篇:
如何提升LLM在某个(组)特定任务上的性能
虽然LLM具有很多能力,但在实际场景中,我们可能只使用其中的一个或一组特定的能力,那如何提升LLM在某个特定任务上的性能呢?答案是:不确定。Fine-tuning
另一个思考就是构造大量的superviseddata直接fine-tuning。Gopher中针对对话任务做了对比实验。Dialog-TunedGopher:fine-tuningGopheron5BtokensofcurateddialogdatasetfromMassiveWebDialog-PromptedGopher:few-shot

可以看到,fine-tuning后的模型性能与直接prompt的基本持平,并没有带来任何提升。
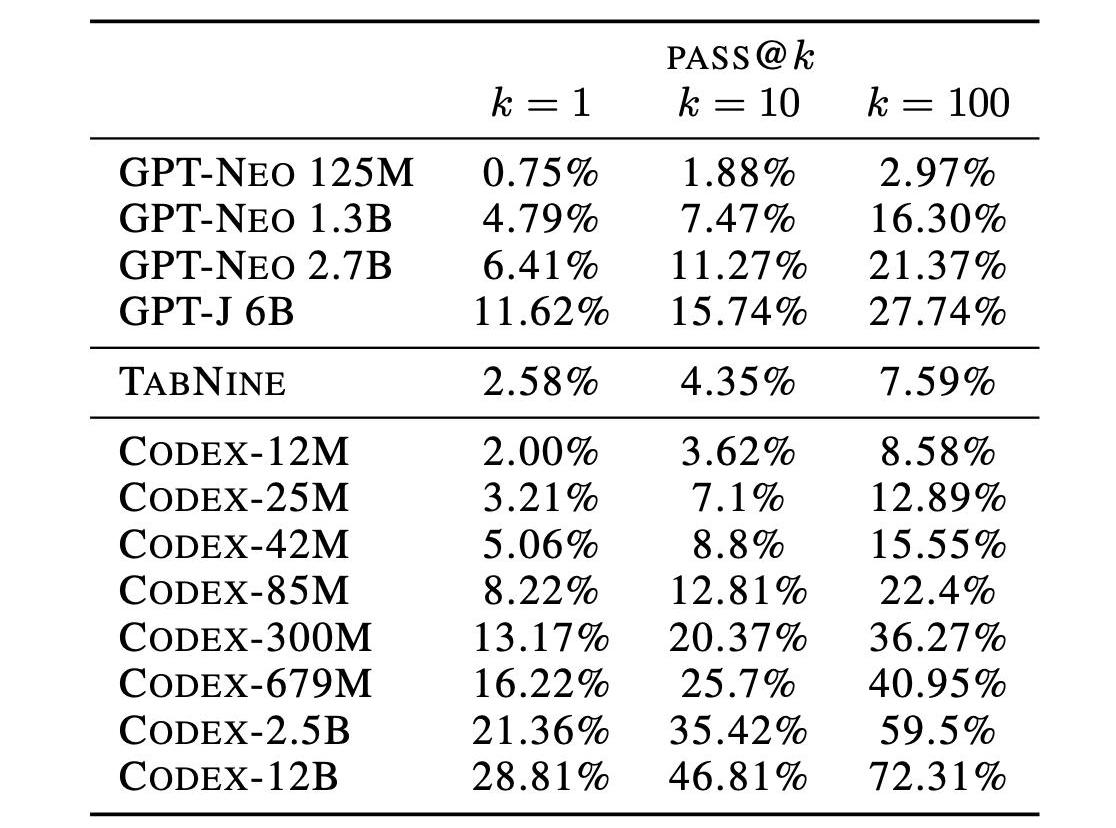
而Codex(GPT-3)针对代码(code)做了fine-tuning,利用159Ggithubcodedata在GPT-3上进行fine-tuning,模型从基本无法处理代码任务提升到当时的SOTA,甚至只需要12B就能达到从0到72%。
Fine-tuningwithhumanfeedback
之前我们提到通过RLHF可以进行alignment,让模型更好的followinstruction。但是,这种对齐也会对模型的性能带来一定的损失,又叫“对齐税”(alignmenttax)。
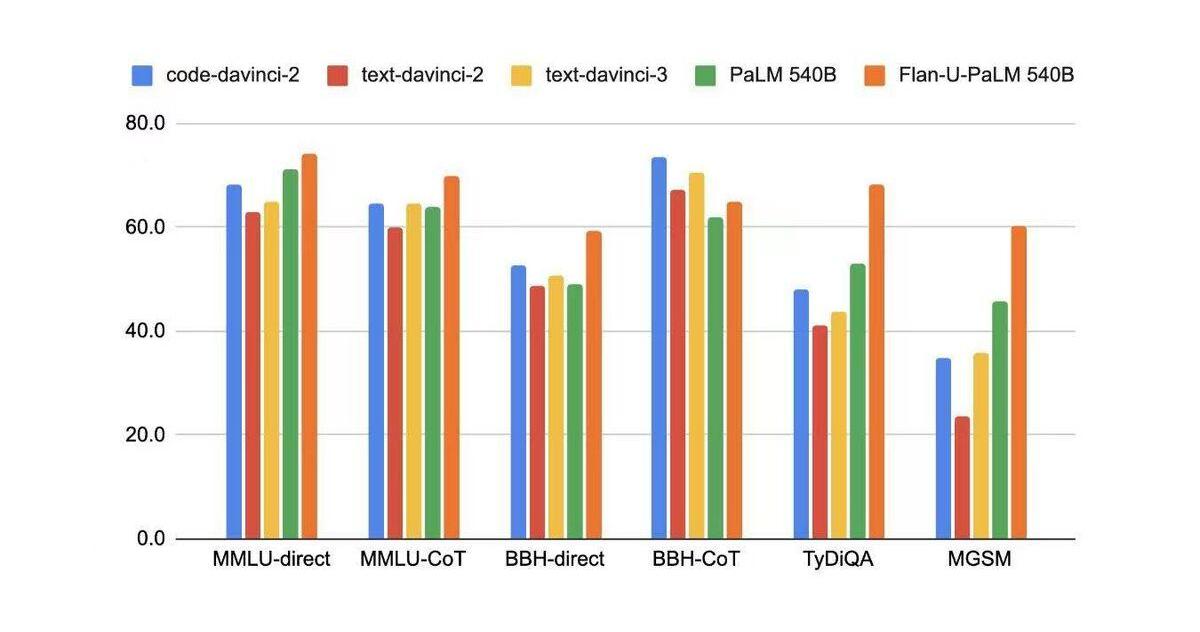
在学术NLP的benchmark上,code-davinci-2(basemodeloftext-davinci-2/text-davinci-3)的性能都是优于fine-tuning后的模型。
RAG
另外一种常用的方案就是RAG
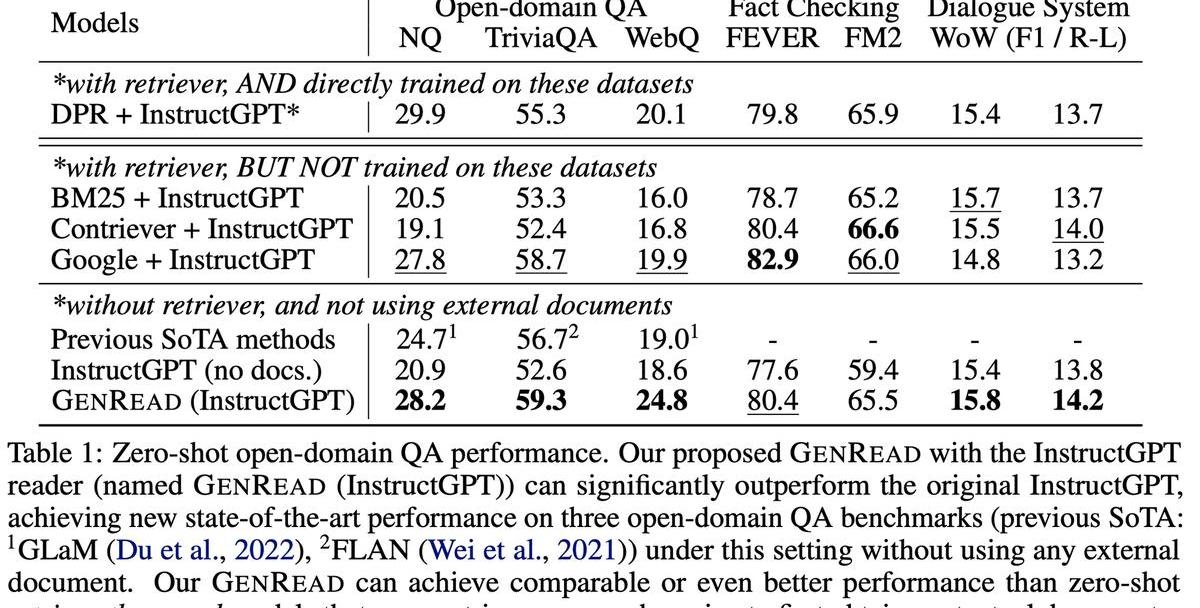
从实验结果上看,RAG能带来一定的提升,但是有限,不如prompt方法带来的提升明显。
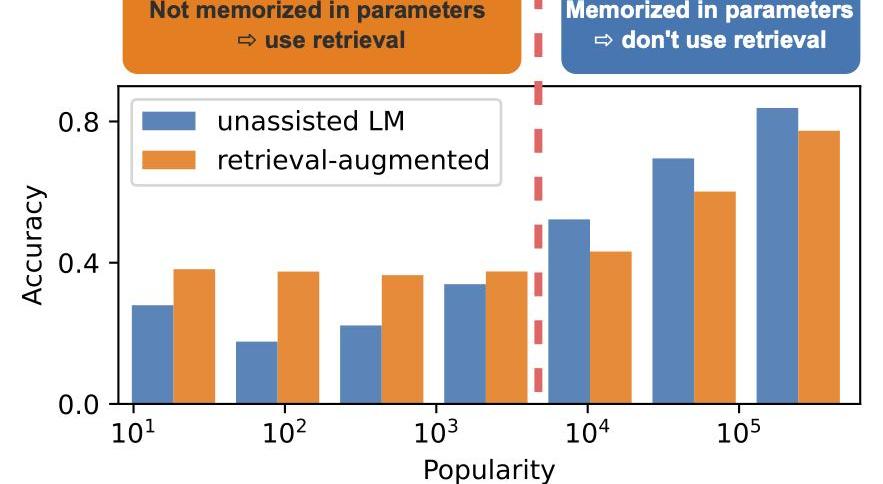
而另一个工作说,RAG是带来提升还是下降跟别的因素有关,如在QA上,他可能跟对应实体的知名度(popularity)有关。LLM已经存储了知名度高的实体信息,而RAG并不能带来性能提升,反而由于retrieval到错误信息而导致性能下降,对于知名度低的实体通过RAG是能带来显著提升的。
PromptEngineering
在CoT出来之前,我们一度认为LLM可能需要继续进行指数级的扩大才能线性提升其推理能力,而CoT的出现解锁了模型的推理能力。所以,一个可能的方案可能是在特定任务上继续寻找他的“般若波罗蜜”。不过笔者认为,这只是一个过渡期而非常态,随着RLHF/Instruction-tuning等方法的发展,未来模型的使用一定会越来越简单便捷。
Instruction-tuning
instruction-tuning已经证明了他的有效性,如flan-t5,flan-PaLM经过instruction-tuning后,其性能都得到了提升。
如何将能力从大模型迁移到小模型上
instruction-tuning,通过大量的instruction-data进行fine-tuning,可以解锁小模型上对应的能力,但是相对大模型,通常还是有差距。压缩模型,如有工作将OPT-175B蒸馏至75B,性能基本无损。。蒸馏,让性能更好的大模型,生成大量的task-data,然后在小模型上进行fine-tuning,但是这可能需要生成很多data,鉴于LLM都比较贵,所以这个可能需要很多钱。
当我们通过钱包地址参与加密活动时,需要签署委托授权书。通常的情况是在将代币转入到冷钱包中后,将其链接到热钱包,然后执行日常的代币授权操作,包括领取空投、玩游戏以及从热钱包加入Discord等.
1900/1/1 0:00:00Optimism的状态L2战争正在升温。上周我们已经了解了Arbitrum的状态,现在我们将目光转向它最大的竞争对手:Optimism.
1900/1/1 0:00:00目录ZKP证明系统的电路实现-基于电路(circuit-based)VS基于虚拟机(vm-based)ZKVM的设计原则STARK-basedVM之间的比较为什么Risc0让人兴奋写在前面:过去.
1900/1/1 0:00:00摘要:据澎湃新闻报道,苏州工信局官方微信公众号1月31日发布《苏州市培育元宇宙产业创新发展指导意见》,提出到2025年培育集聚元宇宙核心企业超200家,元宇宙相关产业规模达2000亿元.
1900/1/1 0:00:00DeFi有什么新故事?每个月我都会跟踪资金流向以找出答案。在熊市获得资金的初创项目很有可能在牛市中蓬勃发展。以下是市场的融资现状和刚刚筹到资金的前5名项目:首先,融资下滑的趋势终于被扭转.
1900/1/1 0:00:00区块链游戏的下一层次就在这里。在这篇文章中,我将从游戏设计的角度解释“条约”的意义。通过链上社交合约,我们现在可以扩大用户生成内容的维度,并挖掘出一个新的可能性领域:用户生成逻辑.
1900/1/1 0:00:00